
선요약
- Data처리량 증가에 대한 가장 빠른 해결방법은 Consumer와 Partition 갯수를 늘리는것이다
- Partition 갯수를 늘릴수는 있지만, 줄일수는 없다.
- Partition을 제거하게되면, 제거된 Partition의 Segment를 재배치 해줘야한다.
- Segment를 재배치 하는 리소스가 복합적으로 너무 방대해서, 해당 기능을 제공하고있지 않다.
이 내용은 인프런 데브원영 강의. 아파치 카프카 애플리케이션 프로그래밍 강의 중, 챕터4에서 나온 내용입니다.
문제상황
kafka-topics.sh 를 사용하여 토픽을 생성합니다. 따로 옵션을 수정하지 않아서 기본옵션으로 생성됩니다.
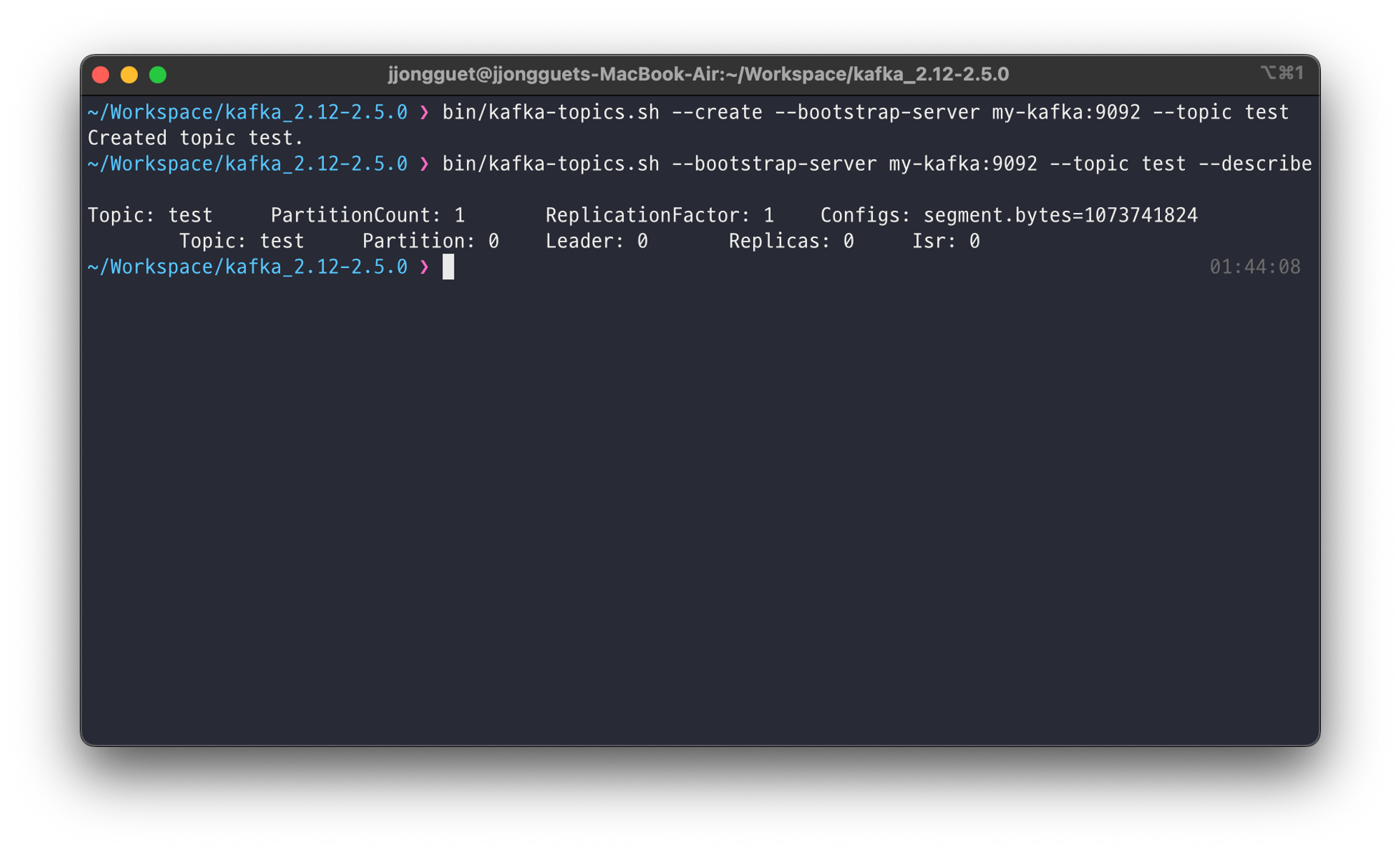
이후 alter 옵션을 사용하여 Partition의 갯수를 10개로 늘립니다

이 부분은 카프카의 핵심입니다. Data처리량이 증가할때 가장 쉬운 방법은 Patition, Consumer의 갯수를늘리는것입니다.
이때 alter 옵션을 사용해서 Partition의 갯수를 5개로 줄여봅니다.
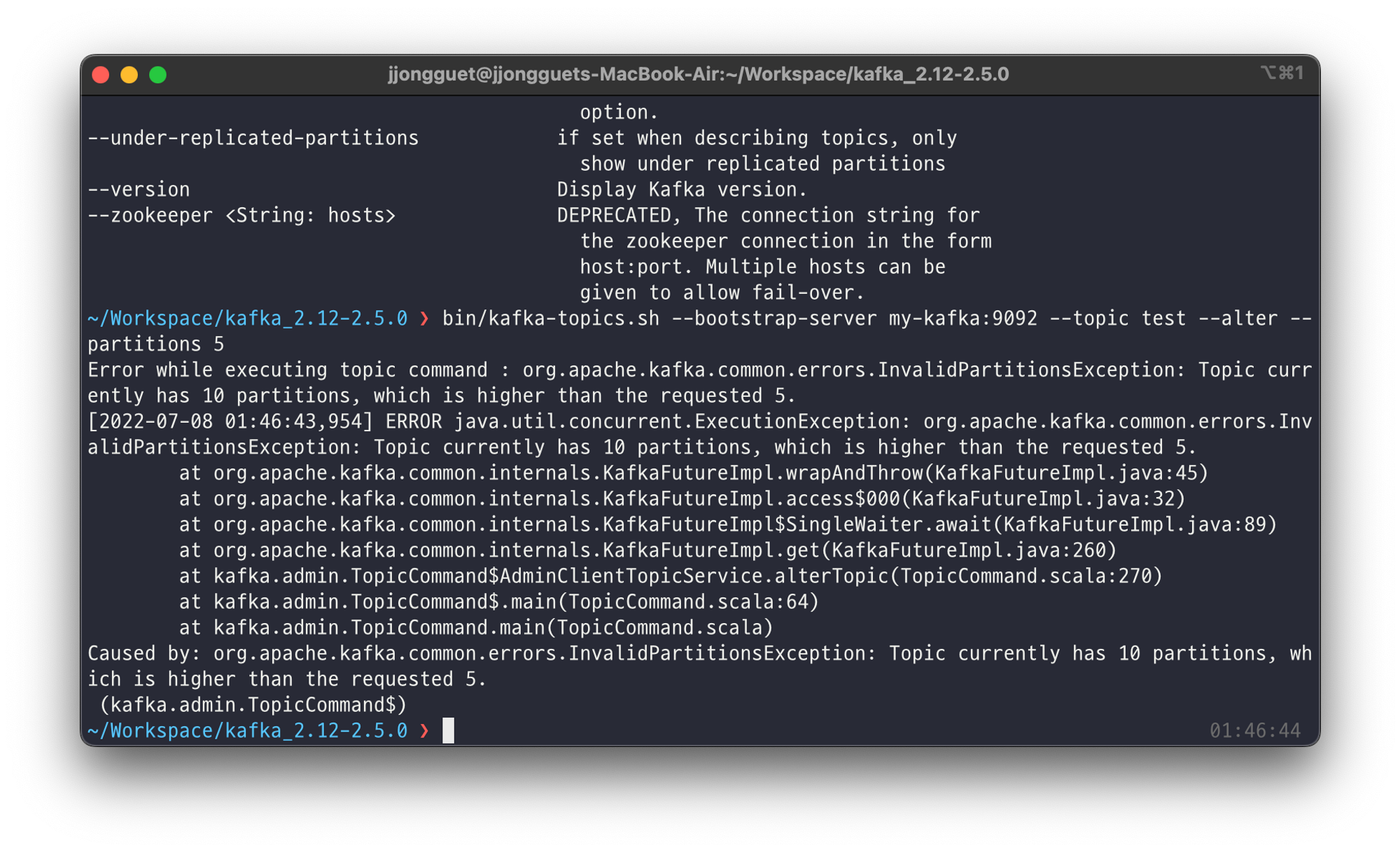
alter옵션을 통해서 파티션의 갯수를 줄이려고하면 InvalidPartitionsException이 발생했습니다.
왜 에러가 날까? (잘못된 생각)
굳이 따지자면 아에 못줄이는것은 아닐것이라고 생각했다.
파티션의 갯수가 늘어나면 문제가없지만, 파티션의 갯수를 줄여버리면 ‘파티션에 저장된 세그먼트는 어떻게 할것인가?’ 가 가장 큰 논점이라고 생각했다.
Hash로 작동되는게 문제였을까? (잘못된 생각2)
사전지식 : Round Robin Partitioner
라운드로빈 은 시스템스케쥴링에서 사용된 단어인데, 쉽게말해 하나씩 모두 골고루 ‘균등하게' 가져가는것이다. 밑에서 나오는 Hash알고리즘 예시도, 그 예다.
사전지식 : Uniform Sticky Partitioner
UniformStickyPartitioner는 2.5.0버전을 기준으로 ‘파티셔너를 지정하지 않은 경우' 에 기본으로 설정되는 옵션이다. Round Robin Partitioner의 특성을 동일하게 상속받았다.
메세지키가 있을때는 ‘메세지 키의 해시값과 파티션을 매칭하여 레코드를 전송' 하는 방식을 사용하기에 동일한 ‘메세지 키' 를 가진 레코드를 하나의 파티션으로 몰아넣을수 있는 기능을 제공한다.
이론적으로 설명해보자
데이터 0~20을 넣으려고 한다.
데이터를 분배하는 Hash알고리즘은 다음으로 정의한다.
Hash(x) = x % {파티션의갯수}
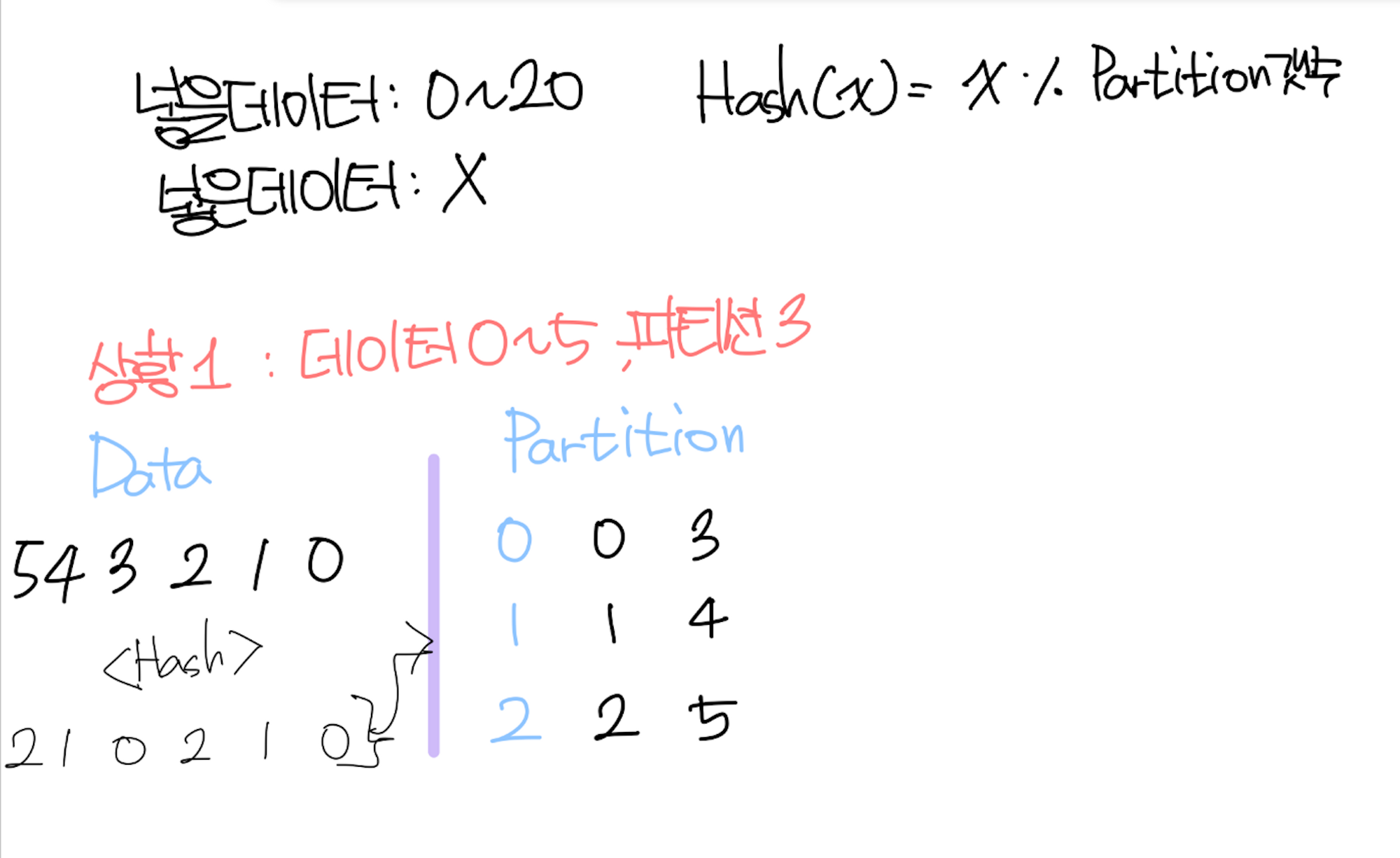
상황1 : 데이터 0~5, 파티션3
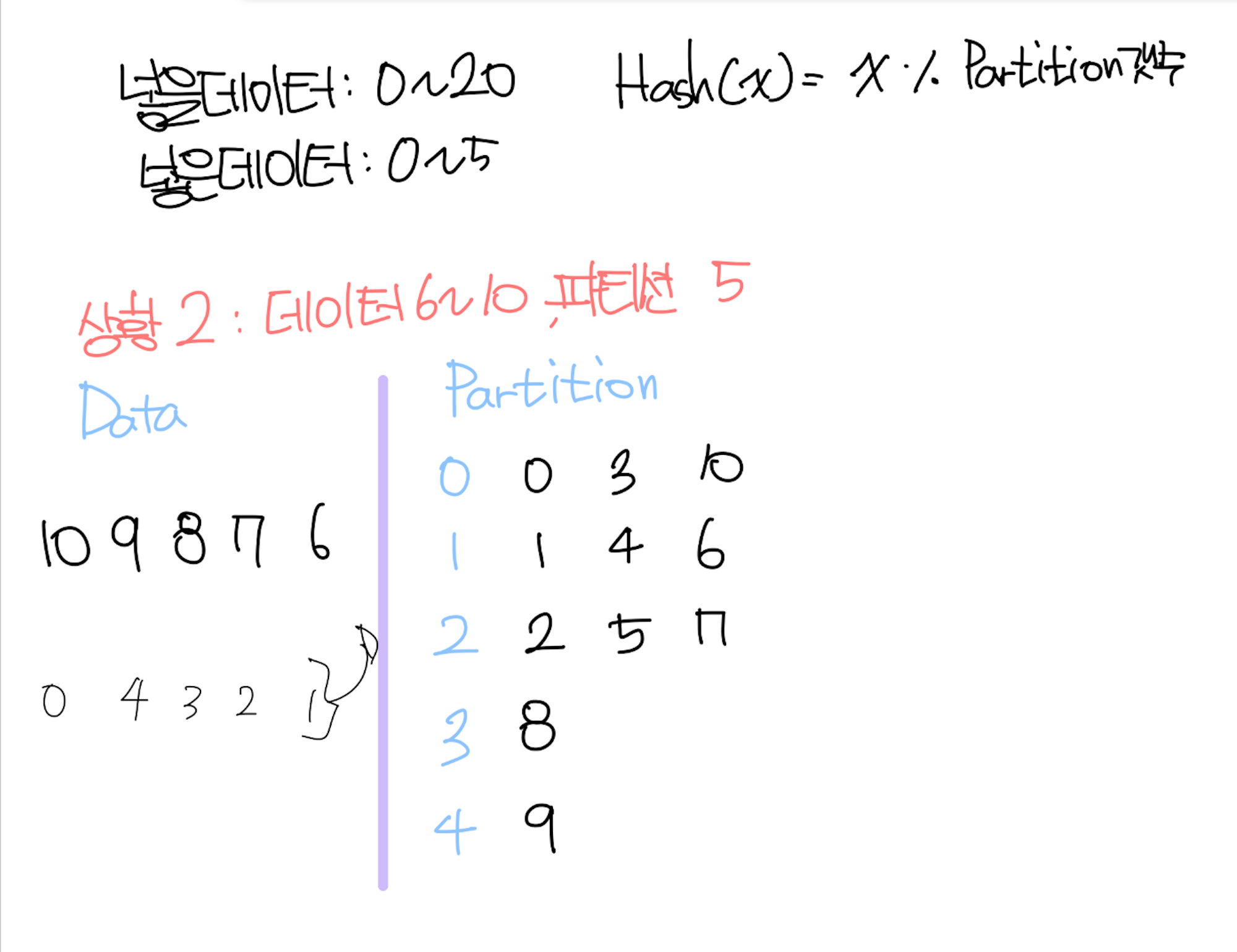
상황2 : 데이터 6~10, 파티션(3→5)
상황3 : 데이터 11~20, 파티션(5→2)

문제가 생겼다. 파티션을 제거하려고 보니, 제거하려는 파티션은 이미 데이터를 가지고있다!
이런 문제를 방지하기위해서 ‘InvalidPartitionsException’ 에러를 만든다.
에러가 나는 이유 (진짜)
파티션의 갯수를 줄이지 못하는 이유는 카프카를 이루는 설계요인이 복합적으로 적용된다.
가장 궁극적인 이유는 ‘다수 브로커에 분배되어있는 세그먼트를 다시 재배열하는것에 상당한 리소스가 사용되기 때문' 이다.
KIP-694(https://cwiki.apache.org/confluence/display/KAFKA/KIP-694%3A+Support+Reducing+Partitions+for+Topics)
Partitioner정책과는 아무 상관이 없다.
참고사항
'DATA Engineering > Kafka' 카테고리의 다른 글
| Scalog 설명. 간단한 요약. (0) | 2022.11.04 |
|---|---|
| Zero-copy 를 위한 노력. Zerializer: Towards Zero-Copy Serialization (0) | 2022.11.01 |
| 챕터4. 기타) 카프카 실습 환경 구성 (0) | 2022.07.20 |
| 섹션4. 카프카 CLI 활용 (0) | 2022.07.20 |
| 섹션3. 카프카 클러스터 운영 (0) | 2022.07.20 |
선요약
- Data처리량 증가에 대한 가장 빠른 해결방법은 Consumer와 Partition 갯수를 늘리는것이다
- Partition 갯수를 늘릴수는 있지만, 줄일수는 없다.
- Partition을 제거하게되면, 제거된 Partition의 Segment를 재배치 해줘야한다.
- Segment를 재배치 하는 리소스가 복합적으로 너무 방대해서, 해당 기능을 제공하고있지 않다.
이 내용은 인프런 데브원영 강의. 아파치 카프카 애플리케이션 프로그래밍 강의 중, 챕터4에서 나온 내용입니다.
문제상황
kafka-topics.sh 를 사용하여 토픽을 생성합니다. 따로 옵션을 수정하지 않아서 기본옵션으로 생성됩니다.
이후 alter 옵션을 사용하여 Partition의 갯수를 10개로 늘립니다
이 부분은 카프카의 핵심입니다. Data처리량이 증가할때 가장 쉬운 방법은 Patition, Consumer의 갯수를늘리는것입니다.
이때 alter 옵션을 사용해서 Partition의 갯수를 5개로 줄여봅니다.
alter옵션을 통해서 파티션의 갯수를 줄이려고하면 InvalidPartitionsException이 발생했습니다.
왜 에러가 날까? (잘못된 생각)
굳이 따지자면 아에 못줄이는것은 아닐것이라고 생각했다.
파티션의 갯수가 늘어나면 문제가없지만, 파티션의 갯수를 줄여버리면 ‘파티션에 저장된 세그먼트는 어떻게 할것인가?’ 가 가장 큰 논점이라고 생각했다.
Hash로 작동되는게 문제였을까? (잘못된 생각2)
사전지식 : Round Robin Partitioner
라운드로빈 은 시스템스케쥴링에서 사용된 단어인데, 쉽게말해 하나씩 모두 골고루 ‘균등하게' 가져가는것이다. 밑에서 나오는 Hash알고리즘 예시도, 그 예다.
사전지식 : Uniform Sticky Partitioner
UniformStickyPartitioner는 2.5.0버전을 기준으로 ‘파티셔너를 지정하지 않은 경우' 에 기본으로 설정되는 옵션이다. Round Robin Partitioner의 특성을 동일하게 상속받았다.
메세지키가 있을때는 ‘메세지 키의 해시값과 파티션을 매칭하여 레코드를 전송' 하는 방식을 사용하기에 동일한 ‘메세지 키' 를 가진 레코드를 하나의 파티션으로 몰아넣을수 있는 기능을 제공한다.
이론적으로 설명해보자
데이터 0~20을 넣으려고 한다.
데이터를 분배하는 Hash알고리즘은 다음으로 정의한다.
Hash(x) = x % {파티션의갯수}
상황1 : 데이터 0~5, 파티션3
상황2 : 데이터 6~10, 파티션(3→5)
상황3 : 데이터 11~20, 파티션(5→2)
문제가 생겼다. 파티션을 제거하려고 보니, 제거하려는 파티션은 이미 데이터를 가지고있다!
이런 문제를 방지하기위해서 ‘InvalidPartitionsException’ 에러를 만든다.
에러가 나는 이유 (진짜)
파티션의 갯수를 줄이지 못하는 이유는 카프카를 이루는 설계요인이 복합적으로 적용된다.
가장 궁극적인 이유는 ‘다수 브로커에 분배되어있는 세그먼트를 다시 재배열하는것에 상당한 리소스가 사용되기 때문' 이다.
KIP-694(https://cwiki.apache.org/confluence/display/KAFKA/KIP-694%3A+Support+Reducing+Partitions+for+Topics)
Partitioner정책과는 아무 상관이 없다.
참고사항
'DATA Engineering > Kafka' 카테고리의 다른 글
| Scalog 설명. 간단한 요약. (0) | 2022.11.04 |
|---|---|
| Zero-copy 를 위한 노력. Zerializer: Towards Zero-Copy Serialization (0) | 2022.11.01 |
| 챕터4. 기타) 카프카 실습 환경 구성 (0) | 2022.07.20 |
| 섹션4. 카프카 CLI 활용 (0) | 2022.07.20 |
| 섹션3. 카프카 클러스터 운영 (0) | 2022.07.20 |