
주의
이 리뷰는 매우 낮은 수준에서 진행한 리뷰입니다. 가볍게 읽기를 권장하며, 관심있으신분들은 원본 자료를 찾아보시기를 권장합니다
*Scalog 논문 : https://www.usenix.org/conference/nsdi20/presentation/ding *발표영상 링크 : https://www.youtube.com/watch?v=pfpjKNZA-d4
NSDI '20 - Scalog: Seamless Reconfiguration and Total Order in a Scalable Shared Log
Key point
- total order shared log → 분산환경에서도 로그가 안꼬여야하고
- unusally scalable → 확장 가능성을 항상 염두해둬야하고
- only totally shared log seamless reconfiguration (without affecting availablity) → 다른 시스템에 의해 영향을 받지 않아야 한다는 것
*오더링(Ordering) : 로그는 순차적으로 쌓이는데, 각각의 로그가 발생한 순서를 매기는것. 발생한 시간이 다르기떄문에, 앞뒤 순서가 존재한다
*샤드(Shard) : 하나의 데이터스토리지라고 이해하기. 해당 게시글에서는 Node(노드) 라는 표현과 병행해서 사용했습니다.
*데이터(data) : 여기서는 Data라고 작성했지만, Log라고 봐도 무방합니다.
Seamless Reconfiguration
시스템의 Config를 바꾼다는것은 분산시스템에서 Partial State가 일어날수도 있다
예를들어 Replica갯수를 기존 3개에서, 4개로 바꾸게 되는 상황이라면 변경전의 어떤 서버는 3개의 replica를 가지고, 변경후의 어떤 서버는 4개의 replica를 가지게되어 서로 다른 replica갯수를 가지게 되는것이다
이때, replica갯수가 3개인 서버는 4개인 서버에게 replica를 3개로 만들기 위해 1개를 줄이라는 명령을 하게되는 상황이 존재할수도있다 이런 상황에서도 문제없이 config를 업데이트 할수있다 라고 하는것이 ‘seamless reconfiguration’ 이다.
(오픈 카카오톡, 한국 데이터 엔지니어 모임, ‘연봉동결’님이 답변해주셨습니다. 감사합니다)
Shared Log
- 각각의 Log는 일종의 set으로써, 들어온 순서가 존재하고, 이에 따라 Ordering이 진행된다
- 각각의 Log는 다양한 클라이언트에 의해 빈번한 읽기, 쓰기가 진행된다
- API를 제공하고 있어서 append, subscribe를 사용하여 읽기, 쓰기를 한다
우리가 Shared Logs에 원하는건 두가지
- Scalability
- 각각의 샤드 내부에 파티셔닝을 통해서 고가용성(high throughput)을 제공
- Seamless Reconfiguration
- 시스템 상에서 장애가 발생해도, 서비스 아키텍쳐의 운영에는 영향을 끼치지말아야함
1. Scalability Total Order
확장성(Scalability)과 Global Ordering에 대한 이슈

분산환경에서 고가용성과 Ordering상에서 강점을 가지는 3가지의 프로그램을 소개함
(분산환경이다보니 Ordering을 노드 하나하나에만 진행하게되는데, 분산환경에 들어오는 전체데이터에 대한 Ordering을 Global Ordering이라고 표현함)
Corfu는 Global Ordering에서 강점을 가지지만 분산노드의 특성상 확장을 염두해두어야하는데, 확장성부분에서는 취약함
Kafka는 확장성에서는 강점을 가지지만 Global Ordering을 제공하지않아서(브로커 내부에서는 Ordering을 유지함), Global Ordering에서는 취약함
고가용성(여기서는 Global Ordering)과 확장성(Scalability)을 함께 만족하는 프로그램은 없음
2. Scalability Seamless Reconfiguration
Log에 대해서, Ordering하는 순서에 대한 이슈
take 1
(1)Client 가 Order/Dissemination프로그램에 Data를 보내고
(2)프로그램에서 Data에 대한 Ordering 을 함께 진행하여 → shard 에 적재하는 방법

Client입장에서 서비스를 진행하기는 쉽겠지만
중앙집중형 아키텍쳐는 (2)과정에서 모든 샤드에 요청을 해야하므로 bottle-neck이 발생할수 있음
(서비스 1개인 경우에는 무리가 없겠지만, 10개..100개…1000개가 된다면 문제가 발생할것)
take 2
(1) client가 Order프로그램에 요청을 보내고
(2) Order프로그램에서 이를 확인하면 응답을 보냄
(3) client가 샤드에 직접 적재하는 방법


take1에 비해서 Bottle-neck은 없겠지만
여러개의 Client에서 Shard에 바로 데이터를 보내기때문에, 모든 Shard에 모든 데이터가 동일하게 있을거라는 보장이없음(seamless reconfiguration 불가)
Scalog
이 모든 문제들을 해결하려고 만든게 scalog

Global Ordering을 지원하고, 확장성까지 가지려고 했음


(1) client가 shard에 log를 기록하고
(2) Shard가 Order프로그램에 local order를 기록하는 요청을 보내면
(3) 프로그램에서 각 Shard에게 total order(Global order)를 제공하는 형식
Ordering 정책
Scalog는 Ordering하는 방식이 조금 특이하다
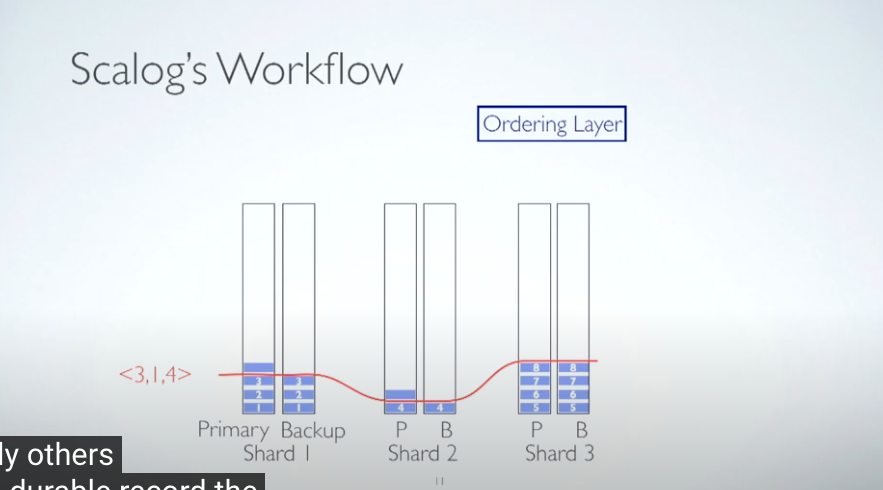
하나의 샤드에는 두가지의 스토리지를 둔다. Primary와 Backup이다
Primary에 log가 작성되면, Backup이 이를 미러링 하는 방식으로 진행을한다
일정한 batch가 되면(여기서는 시간을 예시로 함) Global Order를 매기는데 이때 Primary를 기준으로 Order순서를 지정하는게 아니라 Backup를 기준으로 Global Ordering을 진행한다
즉, 원본데이터에 대한 Global Ordering을 하는게아니라, 원본데이터를 미러링 하는 서버를 대상으로 Global Ordering 을 하는것이다

마찬가지로 이 다음 batch때 Global Order를 매기는데 이때도 Backup에 쌓인 만큼 Global Order가 생성된다

추가적인 샤드가 생성되는 상황에서도 Global Order를 매기는 방식은 동일하다
기존샤드와 추가적인 샤드에서의 Backup를 기준으로 Global Order를 매긴다

장애환경에서도 Global Order매기는 방식은 동일하다
샤드3에서 backup이 장애가 나서 미러링을 하지 못할때에도, 글로벌인덱스는 동일한 기준으로 작동하는것이다 샤드3에 Primary에는 데이터가 있지만, 이를 미러링하지않았다. 따라서 Backup에는 아무 데이터가 없고 인덱스를 매겨주지않는다
이 경우에 샤드3을 사용할수 없게되어 성능상의 이슈가 있겠지만
그래도 정상작동하는 샤드가 존재하기떄문에, 서비스 운영에는 문제가없다
우려되는점과 결론


'DATA Engineering > Kafka' 카테고리의 다른 글
| Kafka에서 서버연결해서 메세지보내기 (0) | 2022.11.08 |
|---|---|
| AWS EC2에 Kafka 설치 및 구축하기 (0) | 2022.11.08 |
| Zero-copy 를 위한 노력. Zerializer: Towards Zero-Copy Serialization (0) | 2022.11.01 |
| Kafka 파티션 갯수를 늘일수있지만, 줄일수없는 이유 : InvalidPartitionsException (0) | 2022.07.20 |
| 챕터4. 기타) 카프카 실습 환경 구성 (0) | 2022.07.20 |
주의
이 리뷰는 매우 낮은 수준에서 진행한 리뷰입니다. 가볍게 읽기를 권장하며, 관심있으신분들은 원본 자료를 찾아보시기를 권장합니다
*Scalog 논문 : https://www.usenix.org/conference/nsdi20/presentation/ding *발표영상 링크 : https://www.youtube.com/watch?v=pfpjKNZA-d4
NSDI '20 - Scalog: Seamless Reconfiguration and Total Order in a Scalable Shared Log
Key point
- total order shared log → 분산환경에서도 로그가 안꼬여야하고
- unusally scalable → 확장 가능성을 항상 염두해둬야하고
- only totally shared log seamless reconfiguration (without affecting availablity) → 다른 시스템에 의해 영향을 받지 않아야 한다는 것
*오더링(Ordering) : 로그는 순차적으로 쌓이는데, 각각의 로그가 발생한 순서를 매기는것. 발생한 시간이 다르기떄문에, 앞뒤 순서가 존재한다
*샤드(Shard) : 하나의 데이터스토리지라고 이해하기. 해당 게시글에서는 Node(노드) 라는 표현과 병행해서 사용했습니다.
*데이터(data) : 여기서는 Data라고 작성했지만, Log라고 봐도 무방합니다.
Seamless Reconfiguration
시스템의 Config를 바꾼다는것은 분산시스템에서 Partial State가 일어날수도 있다
예를들어 Replica갯수를 기존 3개에서, 4개로 바꾸게 되는 상황이라면 변경전의 어떤 서버는 3개의 replica를 가지고, 변경후의 어떤 서버는 4개의 replica를 가지게되어 서로 다른 replica갯수를 가지게 되는것이다
이때, replica갯수가 3개인 서버는 4개인 서버에게 replica를 3개로 만들기 위해 1개를 줄이라는 명령을 하게되는 상황이 존재할수도있다 이런 상황에서도 문제없이 config를 업데이트 할수있다 라고 하는것이 ‘seamless reconfiguration’ 이다.
(오픈 카카오톡, 한국 데이터 엔지니어 모임, ‘연봉동결’님이 답변해주셨습니다. 감사합니다)
Shared Log
- 각각의 Log는 일종의 set으로써, 들어온 순서가 존재하고, 이에 따라 Ordering이 진행된다
- 각각의 Log는 다양한 클라이언트에 의해 빈번한 읽기, 쓰기가 진행된다
- API를 제공하고 있어서 append, subscribe를 사용하여 읽기, 쓰기를 한다
우리가 Shared Logs에 원하는건 두가지
- Scalability
- 각각의 샤드 내부에 파티셔닝을 통해서 고가용성(high throughput)을 제공
- Seamless Reconfiguration
- 시스템 상에서 장애가 발생해도, 서비스 아키텍쳐의 운영에는 영향을 끼치지말아야함
1. Scalability Total Order
확장성(Scalability)과 Global Ordering에 대한 이슈
분산환경에서 고가용성과 Ordering상에서 강점을 가지는 3가지의 프로그램을 소개함
(분산환경이다보니 Ordering을 노드 하나하나에만 진행하게되는데, 분산환경에 들어오는 전체데이터에 대한 Ordering을 Global Ordering이라고 표현함)
Corfu는 Global Ordering에서 강점을 가지지만 분산노드의 특성상 확장을 염두해두어야하는데, 확장성부분에서는 취약함
Kafka는 확장성에서는 강점을 가지지만 Global Ordering을 제공하지않아서(브로커 내부에서는 Ordering을 유지함), Global Ordering에서는 취약함
고가용성(여기서는 Global Ordering)과 확장성(Scalability)을 함께 만족하는 프로그램은 없음
2. Scalability Seamless Reconfiguration
Log에 대해서, Ordering하는 순서에 대한 이슈
take 1
(1)Client 가 Order/Dissemination프로그램에 Data를 보내고
(2)프로그램에서 Data에 대한 Ordering 을 함께 진행하여 → shard 에 적재하는 방법
Client입장에서 서비스를 진행하기는 쉽겠지만
중앙집중형 아키텍쳐는 (2)과정에서 모든 샤드에 요청을 해야하므로 bottle-neck이 발생할수 있음
(서비스 1개인 경우에는 무리가 없겠지만, 10개..100개…1000개가 된다면 문제가 발생할것)
take 2
(1) client가 Order프로그램에 요청을 보내고
(2) Order프로그램에서 이를 확인하면 응답을 보냄
(3) client가 샤드에 직접 적재하는 방법
take1에 비해서 Bottle-neck은 없겠지만
여러개의 Client에서 Shard에 바로 데이터를 보내기때문에, 모든 Shard에 모든 데이터가 동일하게 있을거라는 보장이없음(seamless reconfiguration 불가)
Scalog
이 모든 문제들을 해결하려고 만든게 scalog
Global Ordering을 지원하고, 확장성까지 가지려고 했음
(1) client가 shard에 log를 기록하고
(2) Shard가 Order프로그램에 local order를 기록하는 요청을 보내면
(3) 프로그램에서 각 Shard에게 total order(Global order)를 제공하는 형식
Ordering 정책
Scalog는 Ordering하는 방식이 조금 특이하다
하나의 샤드에는 두가지의 스토리지를 둔다. Primary와 Backup이다
Primary에 log가 작성되면, Backup이 이를 미러링 하는 방식으로 진행을한다
일정한 batch가 되면(여기서는 시간을 예시로 함) Global Order를 매기는데 이때 Primary를 기준으로 Order순서를 지정하는게 아니라 Backup를 기준으로 Global Ordering을 진행한다
즉, 원본데이터에 대한 Global Ordering을 하는게아니라, 원본데이터를 미러링 하는 서버를 대상으로 Global Ordering 을 하는것이다
마찬가지로 이 다음 batch때 Global Order를 매기는데 이때도 Backup에 쌓인 만큼 Global Order가 생성된다
추가적인 샤드가 생성되는 상황에서도 Global Order를 매기는 방식은 동일하다
기존샤드와 추가적인 샤드에서의 Backup를 기준으로 Global Order를 매긴다
장애환경에서도 Global Order매기는 방식은 동일하다
샤드3에서 backup이 장애가 나서 미러링을 하지 못할때에도, 글로벌인덱스는 동일한 기준으로 작동하는것이다 샤드3에 Primary에는 데이터가 있지만, 이를 미러링하지않았다. 따라서 Backup에는 아무 데이터가 없고 인덱스를 매겨주지않는다
이 경우에 샤드3을 사용할수 없게되어 성능상의 이슈가 있겠지만
그래도 정상작동하는 샤드가 존재하기떄문에, 서비스 운영에는 문제가없다
우려되는점과 결론
'DATA Engineering > Kafka' 카테고리의 다른 글
| Kafka에서 서버연결해서 메세지보내기 (0) | 2022.11.08 |
|---|---|
| AWS EC2에 Kafka 설치 및 구축하기 (0) | 2022.11.08 |
| Zero-copy 를 위한 노력. Zerializer: Towards Zero-Copy Serialization (0) | 2022.11.01 |
| Kafka 파티션 갯수를 늘일수있지만, 줄일수없는 이유 : InvalidPartitionsException (0) | 2022.07.20 |
| 챕터4. 기타) 카프카 실습 환경 구성 (0) | 2022.07.20 |