HPA?
용어: Horizontal Pod Autoscaling(수평 스케일링)
구현체: HorizontalPodAutoscaler
의미: 부하 증가(트래픽, 리소스사용량 등) 에 대해 Pod를 더 배치하는것을 뜻한다.
- VPA(Vercital Pod Autoscaling, 수직 스케일링) 은 이미 실행중인 Pod에 더 많은 자원(리소스) 를 할당하는 방식으로 진행되며, HPA와 정반대의 기능이다.
적용대상: 크기 조절이 불가능한 Object(e.g. Daemonset) 를 제외한 Object에 적용가능하다.
HorizontalPodAutoscaler
목표: 워크로드 리소스(deployment, statefulset) 을 자동으로 업데이트하며, 워크로드의 크기를 수요에 맞게 자동으로 스케일링 하는것을 목표로 한다
구현방식: API Resouce & HPA Controller로 구성되어있다.
- API Resource: Controller의 행동을 결정한다.
- HPA Controller: Control-plane내부에서 실행됨. 관측된 리소스메트릭(e.g. CPU, Mem, …) 을 목표 메트릭에 맞추기 위해 목표물(e.g. Deployment)의 적정 크기를 주기적으로 조정한다.
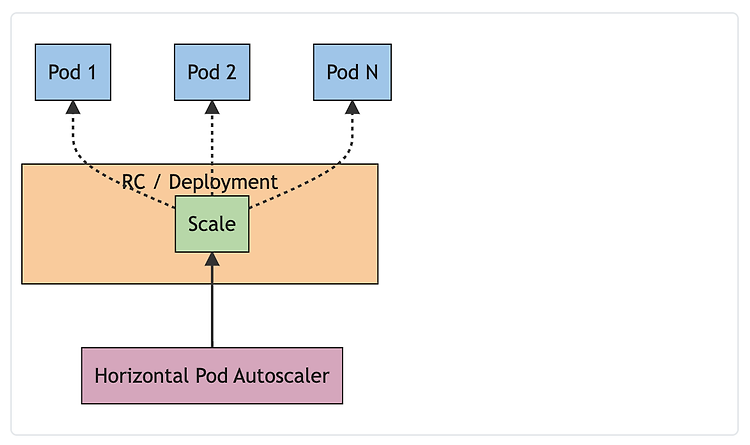
HorizontalPodAutoscaler 가 작동하는 원리
Autoscaler 가 Deployment(Replicaset) 의 크기를 조절하는 방식으로 진행됨

HPA구현방식: HPA를 간헐적으로 실행되는 Control-loop 형태로 구현했다
- 실행주기
- 파라미터:
kube-controller-manager의--horizontal-pod-autoscaler-sync-period - default: 15s
HPA작동원리: 각 주기마다 컨트롤러매니저는 HorizontalPodAutoscaler 정의에 지정된 Metric에 대해, 리소스 사용률을 확인한다.
- 작동방식
- 컨트롤러 매니저:
scaleTargetRef에 정의된 타겟리소스 확인 → 타겟 리소스의.spec.selector레이블 확인 → 레이블에 맞는 파드 선택 → 리소스메트릭(Custom Metrics)API 으로부터 매트릭 수집 - 메트릭
- Pod단위 리소스 메트릭
- 컨트롤러: HorizontalPodAutoscaler 가 대상으로 하는 Pod에 대한 메트릭API 에서 메트릭을 가져옴 → 각 파드의 컨테이너에 대한 동등한 자원요청을 퍼센트(혹은 raw값)로 계산 → 모든 대상 파드에서 사용된 사용률의 평균(혹은 raw값) 을 가져옴 ⇒ 원하는 레프리카의 갯수를 스케일하는데 사용되는 비율을 생성함
- 컨테이너 중 일부에 적절한 리소스요청이 설정되지않는경우: Pod의 CPU사용률은 정의되지않음
- Pod단위 사용자정의 메트릭
- 컨트롤러: 사용률 값이 아닌 raw 값으로 계산해서 사용하는것 부분을 제외하고, Pod단위 리소스 메트릭 방식과 동일함
- Object메트릭, 외부 메트릭
- Object를 표현하는 단일메트릭을 가져옴
HPA를 사용하는 일반적인 방법
- 집약된 API (metrics.k8s.io, custom.metrics.k8s.io, external.metrics.k8s.io)로 부터 메트릭을 가져오는 것
- Metrics Server 라는 애드온을 붙여야만 metrics.k8s.io 가 노출된다.
- GKE에 Metrics Server 애드온이 붙혀져있다.
HPA 컨트롤러의 역할
- 스케일링을 지원하는 워크로드리소스(e.g. Deployment, Statefulset) 에 접근
- 리소스는 각각 scale 이라는 하위리소스를 갖고있으며, 해당하위리소스는 Replica의 수를 결정하고, 각각의현재상태를 확인할 수 있게 하는 인터페이스임
Deployment, HPA 의 Replicas 갯수가 충돌나는 상황
Deployment 는 spec.replicas 필드를 사용하여, 유지하고싶은 Pod 의 갯수를 선언하고
HPA는 spec.minReplicas 필드와 spec.maxReplicas 필드를 사용하여, 유지하는 최소 Pod 와 최대 Pod 갯수를 선언한다.
Deployment 와 HPA 에서 선언하는 형태가 다르다.
Deployment 는 ‘무조건 Pod갯수 유지’ 하는 방식이고, HPA는 ‘최소와 최대를 정해두고, 상황에 맞게 Pod갯수 유지’ 라는 형태로 만들어진다. 따라서, 우선순위가 존재할것이라고 어림짐작할 수 있다.
Q) Deployment 와 HPA 에서 각각 Replicas를 선언하고있는데, 적용되는 우선순위는 ?
A) 정답은 HPA 이다. Deployment 에서 spec.replicas 가 선언되어도, HPA의 spec.minReplicas 와 spec.maxReplicas 를 최우선으로 적용하기때문이다.
예를들어 아래의 Deployment 와 HPA yaml 파일을 배포했다고 가정해보자.
위 경우 Deployment에서는 Replicas 로 5 개를 선언했고, HPA에서는 minReplicas 로 1 개, maxReplicas로 10 를 선언했다.
Deployment와 HPA의 우선순위에 따라서, php-apache 라는 Pod 는 1~10 개를 선언하게된다..
#Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 5
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
#HPA
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
Reference
HPA: https://kubernetes.io/ko/docs/tasks/run-application/horizontal-pod-autoscale/
Deployment, HPA: https://kubernetes.io/ko/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
'Cloud > Kubernetes' 카테고리의 다른 글
| kubectl로 GKE, EKS 접근하기 (0) | 2023.10.26 |
|---|---|
| Minikube 구축하기 (0) | 2023.03.25 |
| Kubernetes Cluster IP no such host : kube-state-metrics 설치 (0) | 2023.03.24 |
| Operator, CRD 간략한 설명 (0) | 2023.03.20 |
| kubeadm init 에러 detected "cgroupfs" as the Docker cgroup driver (0) | 2023.03.19 |
HPA?
용어: Horizontal Pod Autoscaling(수평 스케일링)
구현체: HorizontalPodAutoscaler
의미: 부하 증가(트래픽, 리소스사용량 등) 에 대해 Pod를 더 배치하는것을 뜻한다.
- VPA(Vercital Pod Autoscaling, 수직 스케일링) 은 이미 실행중인 Pod에 더 많은 자원(리소스) 를 할당하는 방식으로 진행되며, HPA와 정반대의 기능이다.
적용대상: 크기 조절이 불가능한 Object(e.g. Daemonset) 를 제외한 Object에 적용가능하다.
HorizontalPodAutoscaler
목표: 워크로드 리소스(deployment, statefulset) 을 자동으로 업데이트하며, 워크로드의 크기를 수요에 맞게 자동으로 스케일링 하는것을 목표로 한다
구현방식: API Resouce & HPA Controller로 구성되어있다.
- API Resource: Controller의 행동을 결정한다.
- HPA Controller: Control-plane내부에서 실행됨. 관측된 리소스메트릭(e.g. CPU, Mem, …) 을 목표 메트릭에 맞추기 위해 목표물(e.g. Deployment)의 적정 크기를 주기적으로 조정한다.
HorizontalPodAutoscaler 가 작동하는 원리
Autoscaler 가 Deployment(Replicaset) 의 크기를 조절하는 방식으로 진행됨
HPA구현방식: HPA를 간헐적으로 실행되는 Control-loop 형태로 구현했다
- 실행주기
- 파라미터:
kube-controller-manager의--horizontal-pod-autoscaler-sync-period - default: 15s
HPA작동원리: 각 주기마다 컨트롤러매니저는 HorizontalPodAutoscaler 정의에 지정된 Metric에 대해, 리소스 사용률을 확인한다.
- 작동방식
- 컨트롤러 매니저:
scaleTargetRef에 정의된 타겟리소스 확인 → 타겟 리소스의.spec.selector레이블 확인 → 레이블에 맞는 파드 선택 → 리소스메트릭(Custom Metrics)API 으로부터 매트릭 수집 - 메트릭
- Pod단위 리소스 메트릭
- 컨트롤러: HorizontalPodAutoscaler 가 대상으로 하는 Pod에 대한 메트릭API 에서 메트릭을 가져옴 → 각 파드의 컨테이너에 대한 동등한 자원요청을 퍼센트(혹은 raw값)로 계산 → 모든 대상 파드에서 사용된 사용률의 평균(혹은 raw값) 을 가져옴 ⇒ 원하는 레프리카의 갯수를 스케일하는데 사용되는 비율을 생성함
- 컨테이너 중 일부에 적절한 리소스요청이 설정되지않는경우: Pod의 CPU사용률은 정의되지않음
- Pod단위 사용자정의 메트릭
- 컨트롤러: 사용률 값이 아닌 raw 값으로 계산해서 사용하는것 부분을 제외하고, Pod단위 리소스 메트릭 방식과 동일함
- Object메트릭, 외부 메트릭
- Object를 표현하는 단일메트릭을 가져옴
HPA를 사용하는 일반적인 방법
- 집약된 API (metrics.k8s.io, custom.metrics.k8s.io, external.metrics.k8s.io)로 부터 메트릭을 가져오는 것
- Metrics Server 라는 애드온을 붙여야만 metrics.k8s.io 가 노출된다.
- GKE에 Metrics Server 애드온이 붙혀져있다.
HPA 컨트롤러의 역할
- 스케일링을 지원하는 워크로드리소스(e.g. Deployment, Statefulset) 에 접근
- 리소스는 각각 scale 이라는 하위리소스를 갖고있으며, 해당하위리소스는 Replica의 수를 결정하고, 각각의현재상태를 확인할 수 있게 하는 인터페이스임
Deployment, HPA 의 Replicas 갯수가 충돌나는 상황
Deployment 는 spec.replicas 필드를 사용하여, 유지하고싶은 Pod 의 갯수를 선언하고
HPA는 spec.minReplicas 필드와 spec.maxReplicas 필드를 사용하여, 유지하는 최소 Pod 와 최대 Pod 갯수를 선언한다.
Deployment 와 HPA 에서 선언하는 형태가 다르다.
Deployment 는 ‘무조건 Pod갯수 유지’ 하는 방식이고, HPA는 ‘최소와 최대를 정해두고, 상황에 맞게 Pod갯수 유지’ 라는 형태로 만들어진다. 따라서, 우선순위가 존재할것이라고 어림짐작할 수 있다.
Q) Deployment 와 HPA 에서 각각 Replicas를 선언하고있는데, 적용되는 우선순위는 ?
A) 정답은 HPA 이다. Deployment 에서 spec.replicas 가 선언되어도, HPA의 spec.minReplicas 와 spec.maxReplicas 를 최우선으로 적용하기때문이다.
예를들어 아래의 Deployment 와 HPA yaml 파일을 배포했다고 가정해보자.
위 경우 Deployment에서는 Replicas 로 5 개를 선언했고, HPA에서는 minReplicas 로 1 개, maxReplicas로 10 를 선언했다.
Deployment와 HPA의 우선순위에 따라서, php-apache 라는 Pod 는 1~10 개를 선언하게된다..
#Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 5
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
#HPA
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
Reference
HPA: https://kubernetes.io/ko/docs/tasks/run-application/horizontal-pod-autoscale/
Deployment, HPA: https://kubernetes.io/ko/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
'Cloud > Kubernetes' 카테고리의 다른 글
| kubectl로 GKE, EKS 접근하기 (0) | 2023.10.26 |
|---|---|
| Minikube 구축하기 (0) | 2023.03.25 |
| Kubernetes Cluster IP no such host : kube-state-metrics 설치 (0) | 2023.03.24 |
| Operator, CRD 간략한 설명 (0) | 2023.03.20 |
| kubeadm init 에러 detected "cgroupfs" as the Docker cgroup driver (0) | 2023.03.19 |