0. 누가 이 글을 읽으면 좋나요?
이 글은 KEDA를 도입하려는 시도를 했으나, 실패했고, 그 과정을 다룬글입니다.
따라서, 쿠버네티스와 HPA에 대한 약간의 지식이 필요합니다.
1. 배경상황과 문제파악
먼저, 현재 환경에 대해 설명하려합니다.
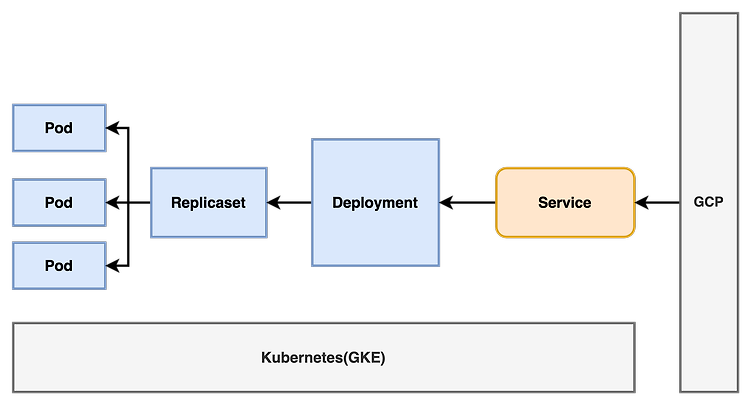
전체 인프라는 Kubernetes(GKE)를 기반으로 하고있고, GKE에서 데모페이지를 배포해놓은 상황이며, Object로 Deployment, Service를 배포했고, GKE에서는 GCP(LB, Load Balancer) 로 배포한 포트를 특정 url 로 연결시켰습니다.
현재 인프라는 아래의 모습으로 배포되어있고, 이해를 돕기 위해 간단한 이미지를 사용합니다.
- 운영측면에서 ’유저 1명이 활동했을때 서비스가 원활히 잘 작동되었다는 점’만 알고있는 상태입니다.
CASE1 : 유저 1명이 서비스를 사용한다.
유저 1명이 사용하는 리소스 소모량과 트래픽을 감당할 수 있게 설계되었기 때문에, 서비스 운영에 아무런 문제가 없습니다.
문제는 이 경우에 발생합니다.
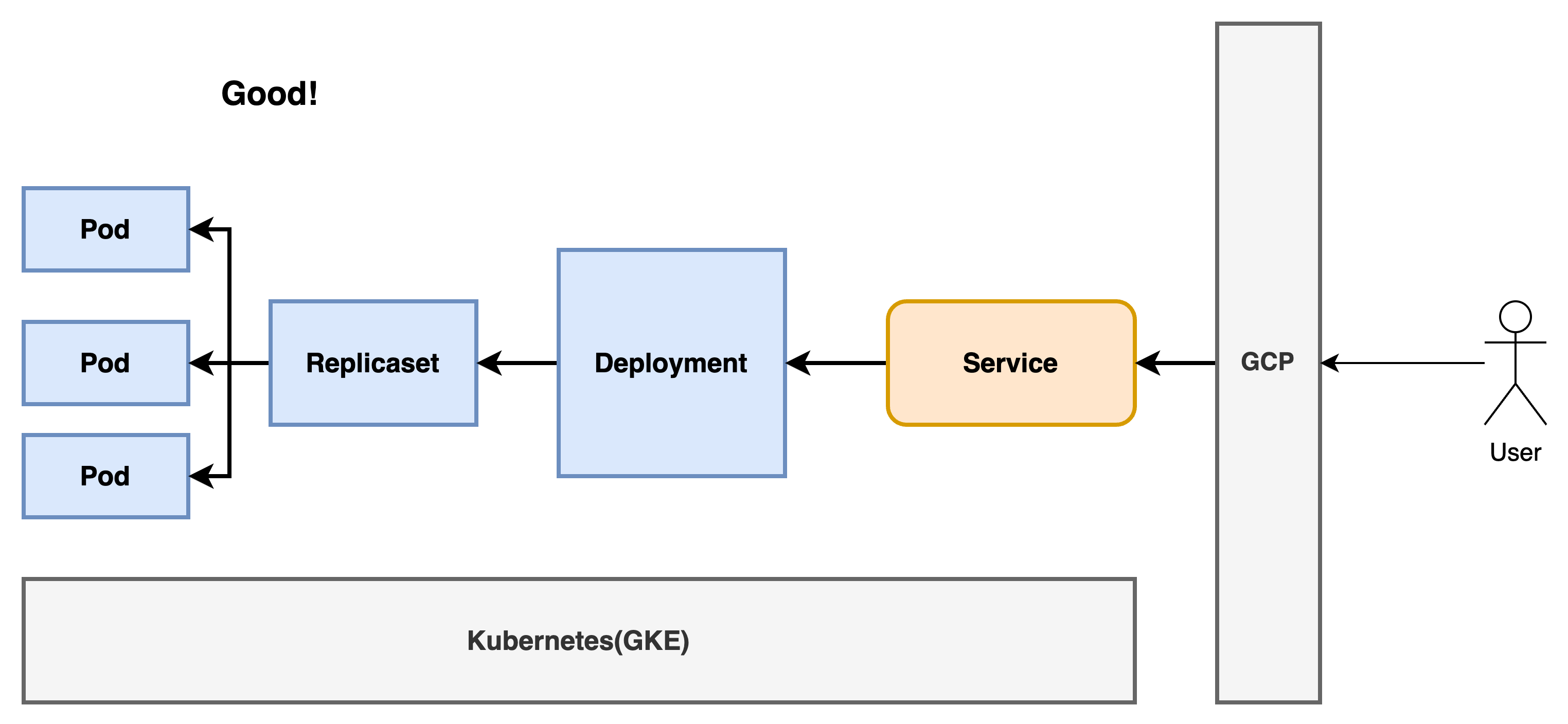
CASE2: 유저 n 명이 서비스를 사용한다.

기존 서비스에서 리소스 소모량과 트래픽을 얼마나 감당가능한지는 모르겠지만
서비스를 사용하는 유저 n 이 무한히 늘어난다면, 어느정도의 인원까지는 감당가능할것이나, 인원이 증가하며 - 서버가 점차 원활하지 않아질 것이고 - 배포한 서비스에서 접속지연이 생기거나, 서비스가 터지는 등의 이슈가 발생할 수 있습니다.
2. 문제가 되는 이유
현재 상황에서 문제점은 2가지입니다.
첫째, 서비스에서 유저의 증가, 감소에 따른 대응을 하지 못한다.
서비스를 구현하고, 1명의 유저가 활동했을때 작동하는 서비스이다. 이는 유저가 10명일때, 100명일때 혹은 n명일때 에 대한 대응을 아무것도 하지 못한다는것을 의미합니다.
유저의 증감에 따라 대응해야하는 리소스와 트래픽 양이 변화하며, 이를 대응해야할 필요성이 존재한다. 이를 대응하지 못한다면 서비스 장애로 이어질가능성이 높습니다.
따라서, 유저의 증감에 따라 대응을 하지 못하는것은 서비스장애로 이어질 가능성이 높습니다.
둘째, (가장중요한점) 기존 서비스가 ‘얼마나 많은 사람의 사용량을 감당할수 있는지’ 인지하지 못했다.
여러가지 이유가 존재하겠지만, 배포한 서비스에 대한 다양한 정보가 부족했습니다.
가령 예를들면, 몇명이 접근해야 서비스에 문제가 생기는지, requests 요청에 따른 response 비율은 어떤지, 몇명이 접근했을때 클라우드비용은 얼마가 나오는지 같은것입니다.
‘서비스가 원활히 작동하는 최대인원은 몇명인가?’ 등등에 대한 기준정보가 없었기 때문에, ‘서비스를 월활히 작동하기위한 목표인원은 몇명인가?’ 에 대한 기준을 잡을 수 없습니다.
따라서, 현재 상태를 제대로 분석하는것이, 서비스 확장의 첫번째 발걸음이 될것 이라고 생각합니다.
3. IDEA1: HPA도입
바로직전에 언급한 두가지 문제를 해결하기 위해 먼저 떠올린건 HPA입니다.
HPA는 특정 Metric 지표를 기반으로, 지표가 임계치에 도달했을때 Scale Out, Scale In 을 하게만드는 대표적인 Kubernetes Object 입니다.
Kubernetes HPA 에서 사용할 수 있는 특정 Metric 의 종류는 꽤나 다양한데, 그중 대표적인 Metric 지표는 CPU, Memory 사용량입니다. 예를들어 특정 Container 의 CPU 사용량이 50% 이상이 되었을때 ScaleOut 을 하는형태로 사용합니다.
또한 Kubernetes HPA 에서는 사전에 정의되어있지 않아서, 유저가 직접 정의해서 사용할수 있는 Metric 을 제공하는데 이를 Custom Metric 이라고 부릅니다. Custom Metric 을 사용하려면 유저가 직접 명세해줘야하기 때문에 신경쓸 부분이 많아집니다.
HPA를 도입함으로써 얻고자 하는 바는 유저 n 명이 활동했을때 원활히 작동하는 서비스를 만드는것입니다. 활동하는 유저가 많아지면 많아질수록 리소스 사용량이 증가할것이기에 CPU, Memory 사용량을 지표삼아도 충분히 그럴듯한 이유가 됩니다.
하지만, CPU, Memory 사용량이 아닌 Requests 요청량을 기반으로 HPA를 트리거받기로 결정했습니다. 그 이유는 Requests사용량을 기반으로 HPA를 하는것이 서비스의 목적에 조금 더 부합하다고 판단했기 때문입니다.
- 일반적으로 Serverless 의 경우에, 여러가지 지표(리소스, 네트워크 레이턴시 등등) 의 지표를 사용할때 RPS(Requests per second) 를 고민하는것 같습니다.
그래서 우리는 Requests 요청량 지표를 도입해야하기에 Custom Metric을 도입하기로 결정했고, 다양한 Object 를 찾아보기 시작했습니다.
4. IDEA2: HPA ⇒ KEDA도입
KEDA는 Kubernetes Event-driven Autoscaling 이라는 말의 줄임으로써, 리소스 메트릭이 아닌, Event 발생수치를 기반으로 Autoscaling을 도와주는 Object 입니다. KEDA는 DOIK2 스터디에서 Kafka On Kubernetes 를 다룰때 알게되었고, 현재 CNCF 졸업프로젝트로 존재합니다.
KEDA 를 고민하게 된 이유는 다음과 같습니다.
- Event-Driven 에 특화되어있기에, 현재 목적에 부합한다.
- KEDA 를 사용하지 않으면 Prometheus 와 Custom Metric 을 직접 도입해야한다.
- 결정적으로 Requests 사용량을 다루는 HTTP Add On 이 존재한다.
조금 자세한 설명을 하자면
- Kubernetes 에서 Custom Metric 을 사용할땐, Prometheus를 DB처럼 사용합니다. 특정 지표가 특정임계값을 충족했는지 알기위해 지속적으로 쿼리하는 방식이며, 이를 Kubernetes 에선 Custom Metric 으로 다루고 있습니다.
- KEDA 는 HTTP Add on 이라는 애드온을 함께 제공하는데, 이를 사용하면 추가적인 Object 의 도입 없이 Requests사용량을 다룰 수 있습니다.
위의 이유때문에 KEDA를 고민했고, KEDA를 사용해보기로 결정했습니다.
5. 개같이 멸망(Pain Point)
일단 결론부터 말하면 KEDA + HTTP Add on 을 도입하기로 한 계획은 실패했습니다.
왜 실패했는지에 대해서 Pain Point 를 잡아보려 합니다.
- 남들이 대부분 시도하지 않는다(제일중요)
- CNCF 졸업프로젝트 인점을 고려했을때, KEDA 프로젝트가 잘못되었다고 생각하지 않습니다.
- 해당 키워드로 검색했을때 참고할만한 레퍼런스가 부족했습니다. 아직은 공식 DOCS만 보고 문제를 해결할 실력은 안되는것 같습니다.
- 분명 지금상황처럼 Requests 사용량을 기반으로 하는 Autoscaling 전략을 추구하는 사람이 있었을것이고, 이를 기술개발블로그에서 포스팅 했을법도 한데, 자료가 거의 없었습니다.
- 왜 남들이 하지 않았을까? 에 대한 고민을 했어야했다고 생각합니다.
- 배포환경에 대한 이해부족
- 현재 Kubernetes 서비스로 GKE(Google Kubernetes Engine) 을 사용중이며, 서비스로의 로드밸런싱을 GCP 에서 진행하고있습니다. 따라서 GCP 에 많은 영향을 받고있고, GCP 에서 설정할 내용이 많았으나 해당부분을 고려하지 못했습니다.
- KEDA에 대한 이해부족
- KEDA 는 특정 프로그램을 대상으로하는 Event 에는 특화되어있습니다. 가령 Apache Kafka, Pulrsa 같은 오픈소스 Message Queue, 클라우드에서 제공하는 AWS CloudWatch, GCP Pub/Sub 에 대해서는 제공정보와 자료가 꽤나 많은것같다. KEDA를 사용하며 배포해야하는 CRD 에 대해서도 이해가 부족했었습니다.
6. 느낀점
1.
아마 여기까지 읽는다면 5.개같이 멸망 에서설명한 PainPoint에 대해 조금 갸우뚱 할 수 있을것 같아 추가내용을 적어보려합니다.
제가 위처럼 생각한 이유는 제 현재직장이 스타트업이기 때문입니다.
스타트업에서는 인원 한명한명의 역할이 critical하게 다가옵니다. 한정된 자원으로 최대의 성과를 만들어내야하고, 한명한명의 대한 파급력이 크게느껴집니다.
비즈니스가 성공하고 새로운 성과를 내는것이 중요하기에, 새로운 것에 리소스를 많이 할당하기 힘든환경이라고 생각합니다.
- 여기서 말하는 리소스는 단순히 비용에 관한것이 아닌 시도에 필요한 시간과 가져올 파급력이라고 생각합니다.
2.
Requests 를 기반으로 Autoscaling 을 해보겠다는 목표로 일주일가량을 소모했는데, 결국 실패했습니다. 이쯤되니 다양한 생각이 듭니다. 예를들면
- 혹시 시간이 조금 더 있었더라면 성공했었을까?
- 내가 GCP, Kubernetes에 대해서 이해도가 높은 상태였다면 어떘을까?
- 성공하더라도 비즈니스적인 파급력이 생각보다 크지 않다면 어떨까?
등등 입니다.
3.
일주일 정도 삽질을 하면서 새롭게배운내용도 많고 신기한것도 많지만, 한편으론 삽질하며 시간만 날린게 아닌가싶습니다. 비즈니스적인 임팩트를 빠르게 만들어 내야하는 상황이라면 많은 사람들이 사용하고 있고, 자료의 양이 많은것을 하나의 기준점 삼아서 기술을 정하는게 가장 가성비있는 결과물을 낼수있지 않을까 싶습니다.
'프로젝트의 고민들' 카테고리의 다른 글
| Notion 서드파티 오픈소스에 기여한 썰 푼다 (0) | 2024.07.17 |
|---|---|
| Devcontainer 로 개발생산성 높이기(부제: Container가 뭐에요?) (4) | 2024.02.05 |
| 소 잃고 외양간 고치기 (3) | 2023.12.15 |
| 티스토리 포스팅 할때 동글(Dong-gle) 사용해본 후기 (2) | 2023.11.13 |
| 올바르게 일하기 (3) | 2023.09.21 |