
INTRO: 주의사항
이 글은 DOIK2 스터디에서 진행한 내용을 바탕으로 작성한 내용입니다. 공부중인 내용이기때문에, 틀린 부분이 있을수 있습니다.
아파치 카프카(Apache Kafka)가 무엇인가요?
위키피디아에서는 아래와 같이 정의하고있습니다.

아파치 카프카(Apache Kafka)는 아파치 소프트웨어 재단이 스칼라로 개발한 오픈 소스 메시지 브로커 프로젝트이다. 이 프로젝트는 실시간 데이터 피드를 관리하기 위해 통일된, 높은 처리량, 낮은 지연시간을 지닌 플랫폼을 제공하는 것이 목표이다. 요컨대 분산 트랜잭션 로그로 구성된[3], 상당히 확장 가능한 pub/sub 메시지 큐로 정의할 수 있으며, 스트리밍 데이터를 처리하기 위한 기업 인프라를 위한 고부가 가치 기능이다.
핵심키워드
핵심 키워드는 다음과같습니다.
- 오픈소스: 아파치 오픈소스 프로젝트로 진행되고있습니다
- 메세지 브로커: 송신자(보내는 애플리케이션) 과 수신자(받는 애플리케이션)가 존재하고, 중간에서 전달해주는 역할. ‘송신자와 수신자는 서로에 대한 정보가없어도, 브로커의 정보만 알고있다는것이 핵심입니다.
- 트랜잭션로그: DataBase에서 주로 사용되는 표현. 변경 기록을 Log로 남겨서, 쉽게 Rollback할수 있게 만들수 있습니다.
- 분산트랜잭션: 2개 이상의 네트워크 상의 시스템 간의 트랜잭션(변경기록). 일반적으로 ACID를 위해서 사용합니다.
- pub/sub 메세지 큐: 발행-구독 모델 이라고도 표현함. 송신자 와 수신자의 역할이 구분되어있고, 전달할때 ‘QUEUE’ 방식으로 진행된다는 것을 의미합니다.
카프카는 왜 만들어졌나요?
카프카가 만들어지게 된 이유를 알아보고자합니다.
아래의 사진은 카프카를 사용하고있는 데이터파이프라인 구성도입니다.
[N개의 데이터소스] - [Apache Kafka] - [M개의 서비스] 로 구성되어있는것을 볼 수 있습니다.
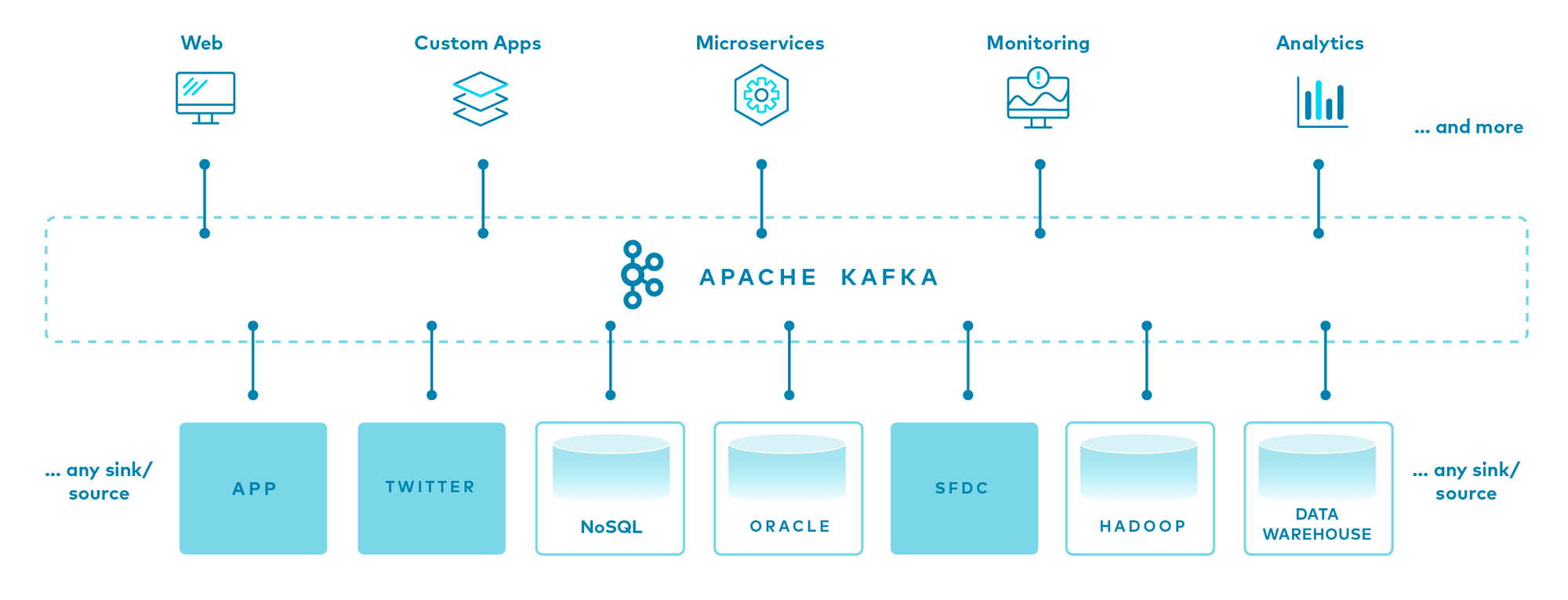
왜 하필 중간에 [Apache Kafka]가 있어야할까요?
만약, [N개의 데이터소스] 와 [M개의 서비스] 가 모두 1:1로 연결되어있다면 뭐가 문제일까요?
Apache Kafka를 만들기 전, 링크드인의 시스템아키텍쳐는 이렇게 생겼었습니다.
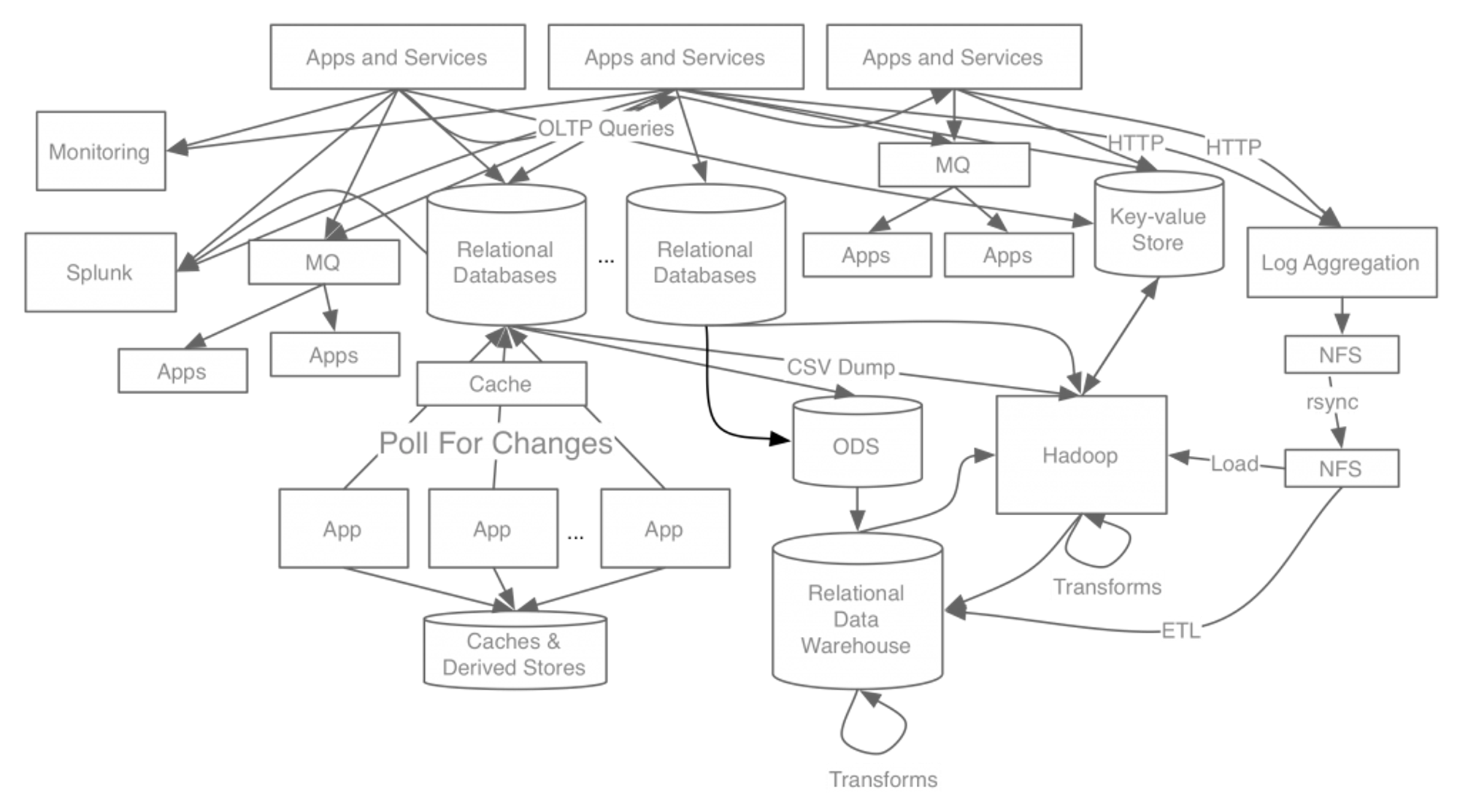
이제 질문하나 해보겠습니다. 만약 ‘Relational Databases’에서 데이터 유실이 발생했다면, 영향을 받는 부분은 어떤부분인가요? 또한, 데이터 유실을 문제를 해결하기위해 확인해야할 부분은 어느부분인가요?
카프카가 만들어진 이유중 하나는 ‘장애가 발생했을때 문제를 쉽게 해결하기 위함’입니다. 위의 아키텍쳐를 단순화시켜서, 아래처럼 만드는것이죠.
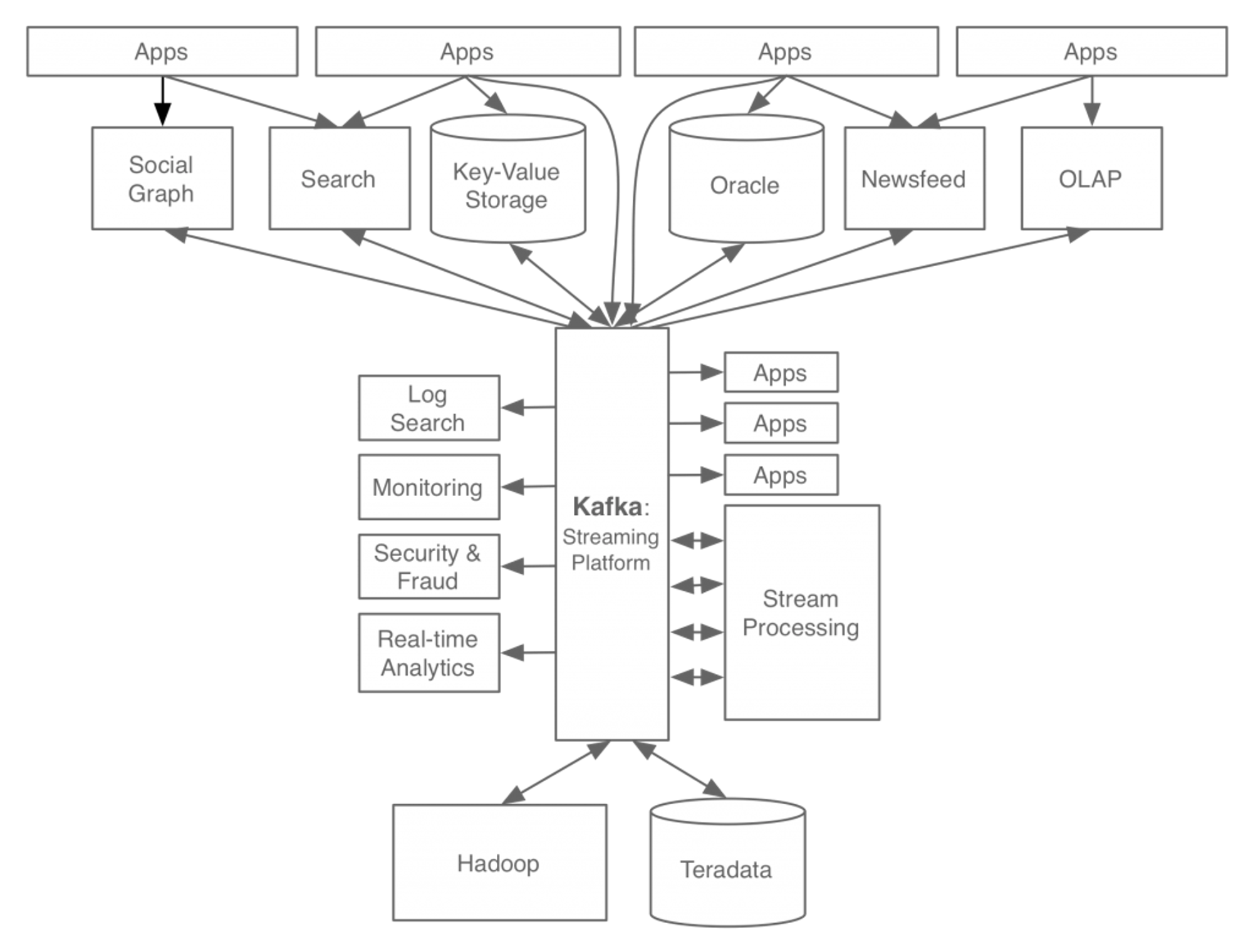
아키텍쳐가 매우 간단해졌습니다. 어디선가 장애가 발생해도, 쉽게 해결할수 있을것같습니다. 여기서는 카프카의 한가지 목적만 설명했지만, 수 많은 이유로 Kafka 는 스트리밍플랫폼의 중심 역할을 담당하게되었고, 데이터파이프라인의 중추 자리를 맡게 되었습니다.
- Kafka는 단일 인스턴스로 사용하는 것보다, 여러개의 인스턴스를 하나의 클러스터로 묶어서 사용하는게 일반적입니다.
- 위 문서에서는 Kafka와 Kafka Clsuter를 혼재하여 사용하고있습니다.
카프카의 주요 특징은 뭔가요?
- 높은 처리량: 배치처리를 진행하기때문에, 대용량 실시간 로그 처리에 적합합니다.
- 확장성: 브로커(일반적으로는 인스턴스의 개념) 의 Scale In/Out 이 용이합니다.
- 영속성: 전송받은 데이터를 메모리에 저장하지않고, 파일시스템에 저장하는 방식입니다.
- PageCache 를 사용하여 OS레벨에서 IO성능을 향상시켰습니다.
- Official Kafka Confluence: https://cwiki.apache.org/confluence/display/INCUBATOR/KafkaProposal#Background
- PageCache 를 사용하여 OS레벨에서 IO성능을 향상시켰습니다.
KafkaProposal - INCUBATOR - Apache Software Foundation
Abstract Kafka is a distributed publish-subscribe system for processing large amounts of streaming data. Proposal Kafka provides an extremely high throughput distributed publish/subscribe messaging system. Additionally, it supports relatively long term per
cwiki.apache.org
용어설명
먼저 정확한 용어 설명을 하겠습니다.
- 주키퍼 ZooKeeper : 카프카의 메타데이터 관리 및 브로커의 정상 상태 점검 health check 을 담당
- IMPORTANT : KRaft mode is not ready for production in Apache Kafka or in Strimzi - Link
- 카프카 Kafka 또는 카프카 클러스터 Kafka cluster : 여러 대의 브로커를 구성한 클러스터를 의미
- 브로커 broker : 카프카 애플리케이션이 설치된 서버 또는 노드를 말함
- 프로듀서 producer : 카프카로 메시지를 보내는 역할을 하는 클라이언트를 총칭
- 컨슈머 consumer : 카프카에서 메시지를 꺼내가는 역할을 하는 클라이언트를 총칭
- 토픽 topic : 카프카는 메시지 피드들을 토픽으로 구분하고, 각 토픽의 이름은 카프카 내에서 고유함
- 파티션 partition : 병렬 처리 및 고성능을 얻기 위해 하나의 토픽을 여러 개로 나눈 것을 말함
- 세그먼트 segment : 프로듀서가 전송한 실제 메시지가 브로커의 로컬 디스크에 저장되는 파일
- 메시지 message 또는 레코드 record : 프로듀서가 브로커로 전송하거나 컨슈머가 읽어가는 데이터 조각을 말함
기본동작
컴포넌트에 대해서 설명을 하겠습니다.
- 카프카는 데이터를 받아서 전달하는 데이터 버스 data bus 의 역할
- 카프카에 데이터 (메시지) 를 만들어서 주는 쪽은 프로듀서 producer 라 부르고, 데이터를 빼내서 소비하는 쪽은 컨슈머 consumer 라 함
- 주키퍼는 카프카의 정상 동작을 보장하기 위해 메타데이터 metadata (브로커들의 노드 관리 등) 를 관리하는 코디네이터 coordinator 임
- 프로듀서와 컨슈머는 클라이언트이며, 애플리케이션은 카프카와 주키퍼임
- 카프카는 프로듀서와 컨슈머 중앙에 위치하여, 프로듀서로부터 전달 받은 메시지들을 저장하고 컨슈머에 메시지를 전달함
- 컨슈머는 카프카에 저장된 메시지를 꺼내오는 역할을 함
- 브로커 broker 는 애플리케이션이 설치된 서버 또는 노드를 의미
- 리플리케이션 replication : 각 메시지들을 여러 개로 복제해서 카프카 클러스터 내 브로커들에 분산시키는 동작을 의미
- 하나의 브로커가 종료되더라도 카프카는 안정성을 유지할 수 있음
- 토픽 생성 명령어 중
replication-factor 3이면, 원본을 포함한 리플리케이션(토픽의 파티션)이 총 3개를 의미함- 원본(토픽의 파티션)을 리더 reader, 리플리케이션을 팔로워 follower
- 리더는 프로듀서, 컨슈머로부터 오는 모든 읽기/쓰기를 처리, 팔로워는 리더로부터 복제 유지
- 파티션 partition : 토픽 하나를 여러 개로 나눠 병렬 처리가 가능하게 만들 것을 의미
- 나뉜 파티션의 수 만큼 컨슈머를 연결 할 수 있어서, 병렬 처리가 가능함
- 파티션 수는 초기 생성 시 언제든지 늘릴 수 있지만 늘린 파티션은 줄일 수 없음, 컨슈머 LAG 모니터링으로 판단 할 것
- 컨슈머 LAG (지연) = ‘프로듀서가 보낸 메시지 갯수(카프카에 남아 있는 메시지 갯수)’ - 컨슈머가 가져간 메시지 갯수’
- 세그먼트 segment : 토픽의 파티션에 저장된 메시지들이 세그먼트라는 로그 파일의 형태로 브로커의 로컬 디스크에 저장됨
- 오프셋 offset : 파티션에 메시지가 저장되는 위치, 오프셋은 순차적으로 증가(0, 1, 2...)
Kafka 입장에서 보는 아키텍쳐의 구성
전체 아키텍쳐를 Kafka관점에서
전체 아키텍쳐를 Kafka 관점에서 봤을땐, 아래처럼 3가지 컴포넌트의 구성으로 볼수 있습니다.
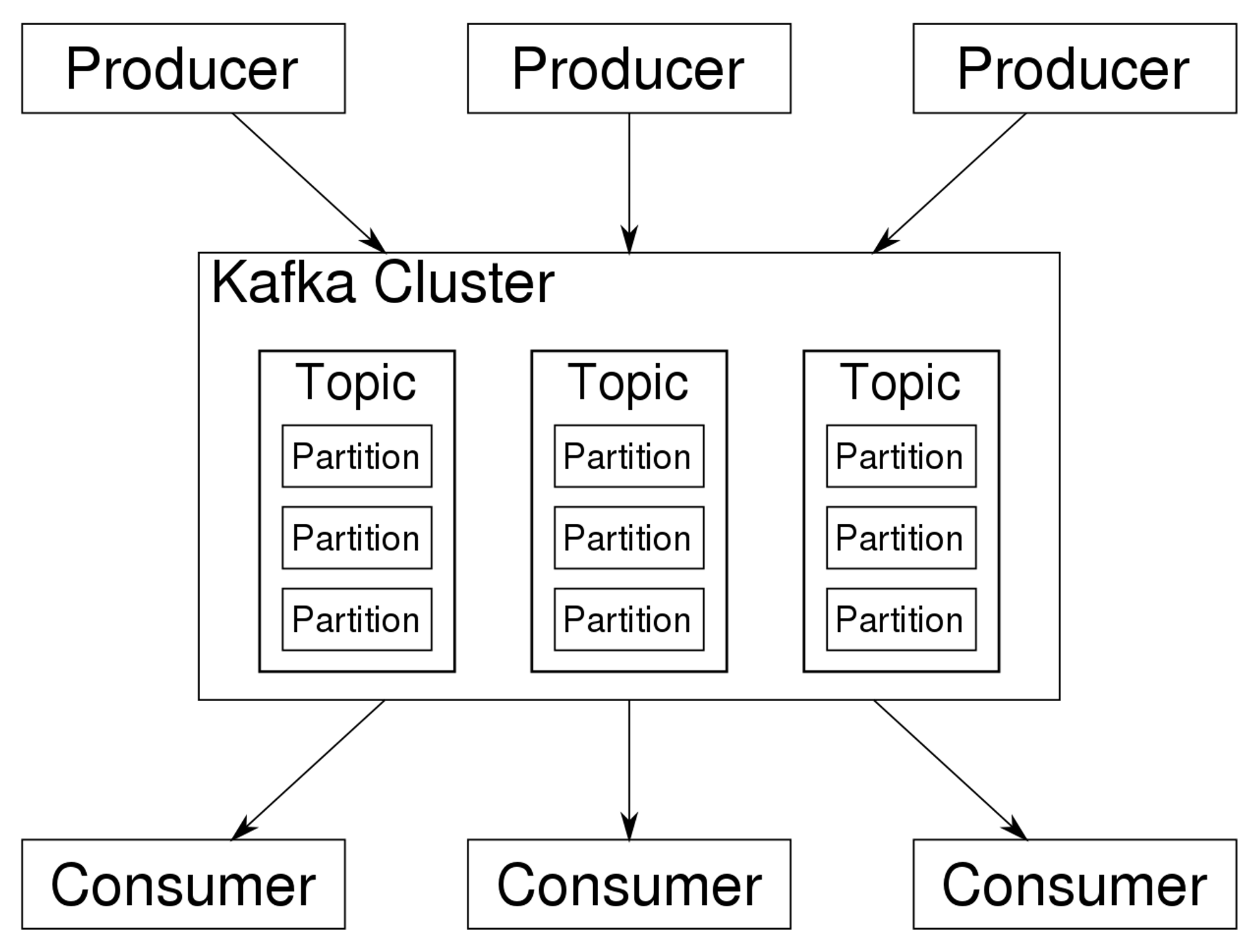
- Producer(프로듀서)
- Kafka Cluster(카프카 클러스터)
- Consumer(컨슈머)
카프카 클러스터 내부에는 Topic이 존재하며, Topic 내부에는 Partition이 존재한다는것을 확인 할 수 있습니다.
Producer 는 Kafka 로 PUSH 하고있고, Consumer는 PULL하고 있는것을 확인할 수 있습니다.
또한, Kafka로 PUSH하는 대상을 Producer라고 부르고, Message를 Publish한다고 지칭하며
Kafka에서 SUBSCRIBE하는 대상을 Consumer라고 부르고, Message를 Subscribe한다고 지칭합니다.
이때 Publish/Subscribe의 앞글자를 따서 PUB/SUB 모델이라고 부르기도 합니다.
또한, 위의 그림에서 화살표의 방향을 유심히 봐야하는데, 사실 위의 그림은 반은맞고 반은틀렸습니다.
메세지는 Producer → Kafka Cluster → Consumer 로 흐릅니다. 그러나, 메세지를 가져가는 방향이 틀렸습니다.
메세지를 Consumer관점에서
Producer는 Kafka로 메세지를 publish(send) 합니다.
그렇다면 Consumer는 어떨까요? Kafka가 메세지를 publish해줄까요?
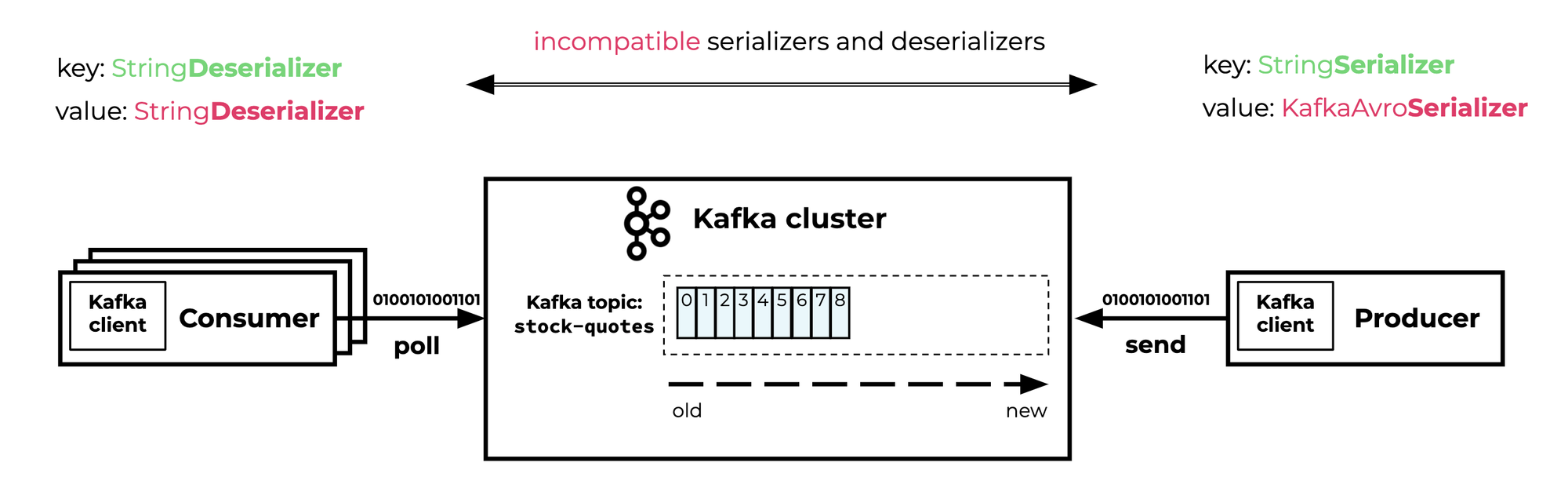
Kafka가 Consumer로 메세지를 Publish(send) 하는것이 아닙니다. 정답은 Consumer가 Kafka 에서 메세지를 Subscribe(poll) 하는 것입니다.
Kafka Cluster에서 Consumer로 메세지를 보내주는것이아니라, Consumer가 Kafka Cluster에서 메세지를 꺼내간다는 표현이 조금 더 정확한것 같습니다.
조금 더 자세하게 봅시다.
Producer와 Consumer의 작동
바로 직전에 ‘Producer는 Kafka로 메세지를 publish(send)합니다’ 라고 써있습니다. 이를 조금 더 정확한 표현으로 바꿔보려고합니다.
위 표현은 ‘Producer는 Kafka를 구성하고있는 Broker로 메세지를 publish(send)합니다.’ 라고 바꿀수 있습니다.
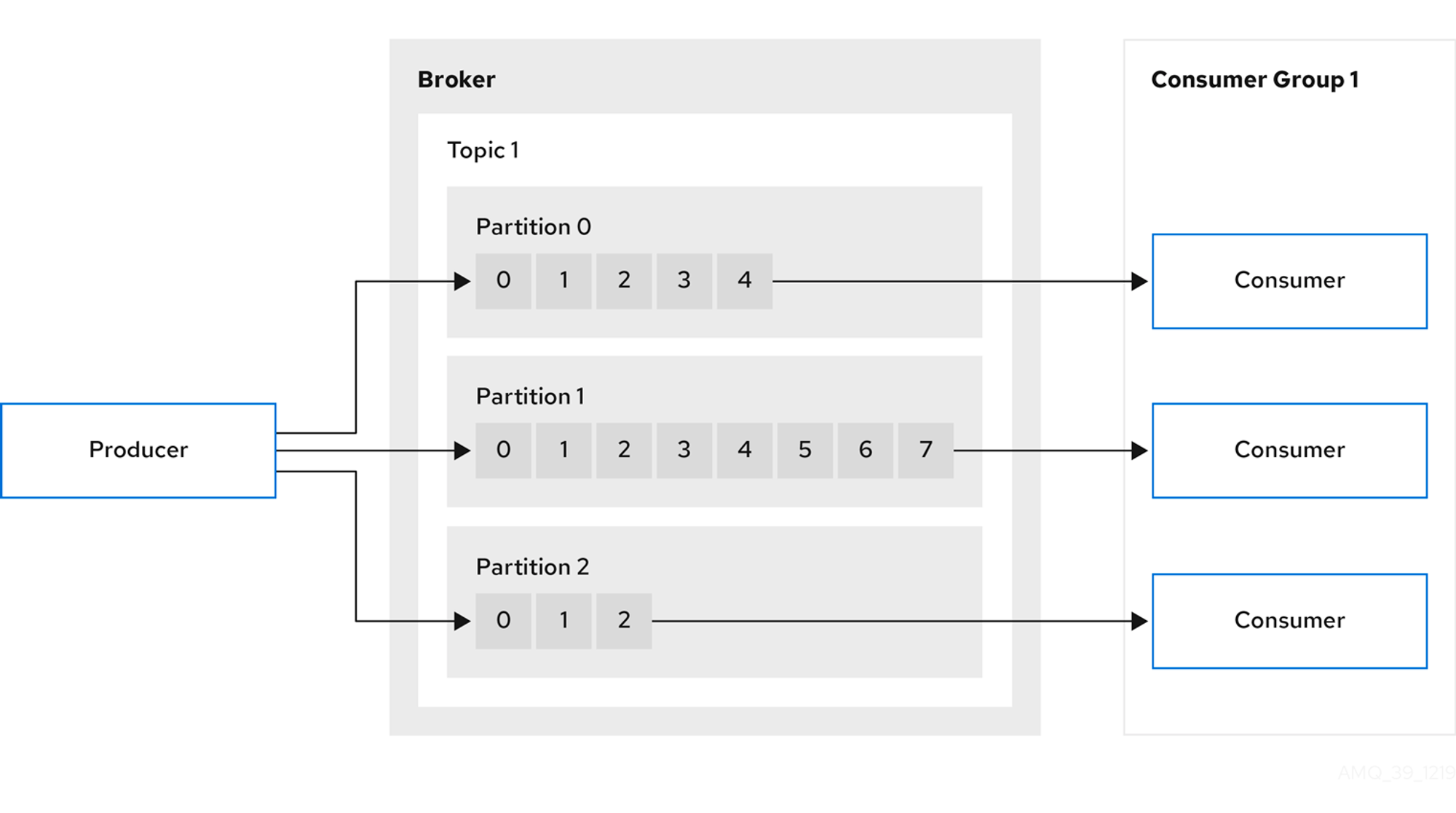
Broker내부에는 Topic이 존재하고, Topic내부엔 Partition이 존재합니다. Producer에서 전송된 메세지는 Partition에 순서대로 차곡차곡 적재됩니다.
Consumer는 Partition에 있는 메세지를 순서대로 가져갑니다. Consumer들을 묶어서 ConsumerGroup으로 관리할 수 있습니다.
잠시만요, Producer의 쓰기속도와 Consumer의 읽기속도가 다를수있지않나요?

Topic 내부의 단일 Partition으로 보면 이해가 쉽습니다.
Partition의 중요한 특징은 메세지가 ‘순차적’으로 적재된다는것입니다. 즉, Paritition내부에서는 옛날에 들어온 메세지부터 최근에 적재된 메세지까지 적재되고, 들어온 순서를 보장한다는 뜻입니다.
Producer가 메세지를 전송하면 Partition의 맨 뒤에 적재(write)됩니다. Consumer는 맨 앞부터 메세지를 읽고(read)있습니다. Producer가 적재한 메세지의 번호와 Consumer가 읽어간 메세지의 번호의 차이를 Consumer LAG(컨슈머 랙) 이라고 합니다.
- 그림에서 Producer는 메세지7을 적재했고, Consumer는 메세지5를 읽었습니다.
- 이때 Consumer LAG은 7(write) - 5(read) 이며, 2만큼 LAG이 있다고 표현합니다.
이번 게시글에서는 ‘이런내용이 있고, Producer와 Consumer때문에 LAG이 발생할 수 있다’ 라고만 이해하고있으면 됩니다.
이제 큰 그림에서 봅시다.
카프카의 컴포넌트
카프카 클러스터를 중심으로, 관련된 컴포넌트는 다음과 같습니다.
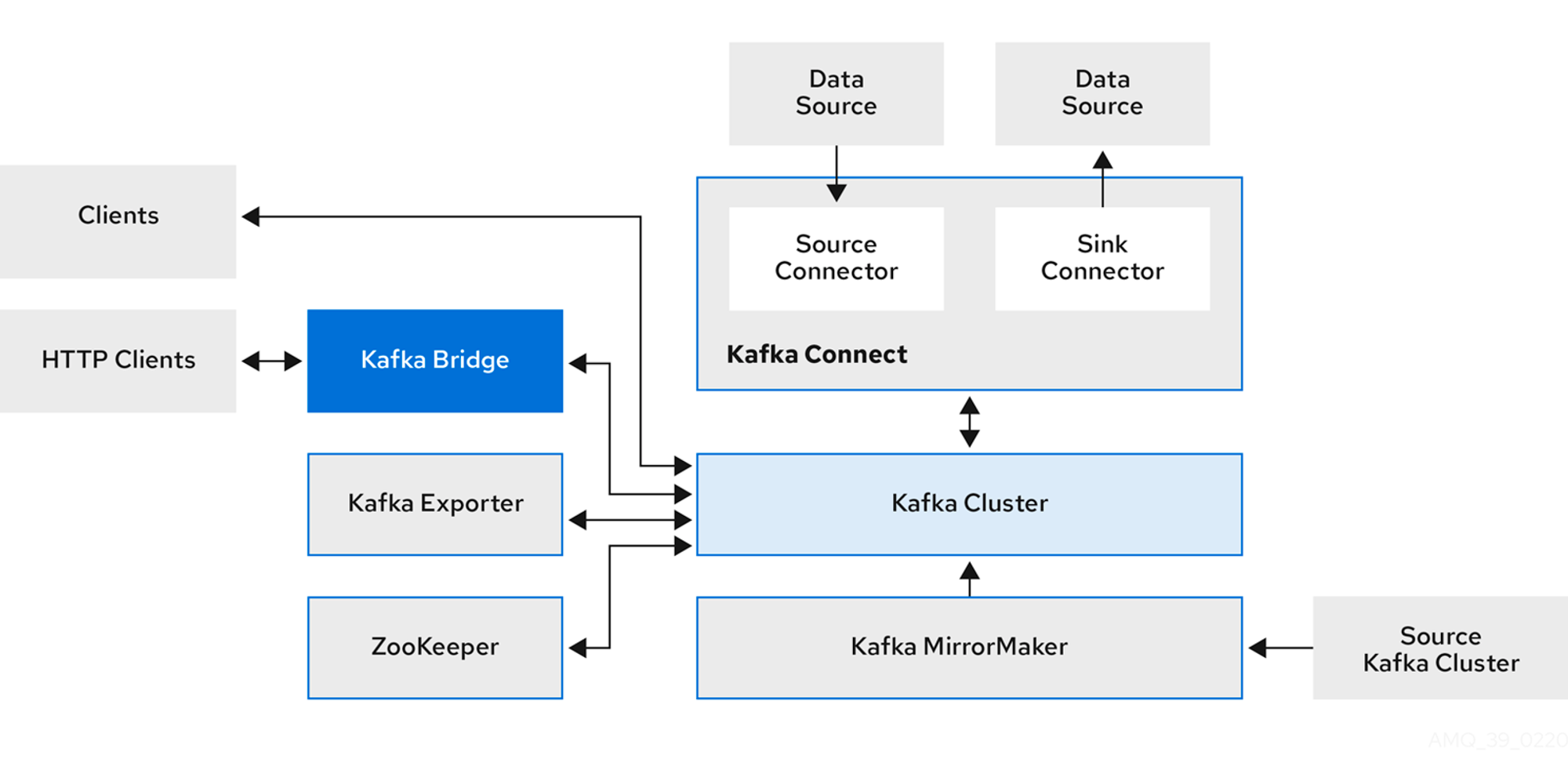
아래에서는 컴포넌트에 대한 설명을 하나씩 할것이며, 일반적인 컴포넌트와 Strimzi에서의 컴포넌트의 구성을 설명합니다.
카프카 커넥트(Kafka Connect)
데이터베이스와 같은 외부시스템을 카프카와 연결해줍니다.
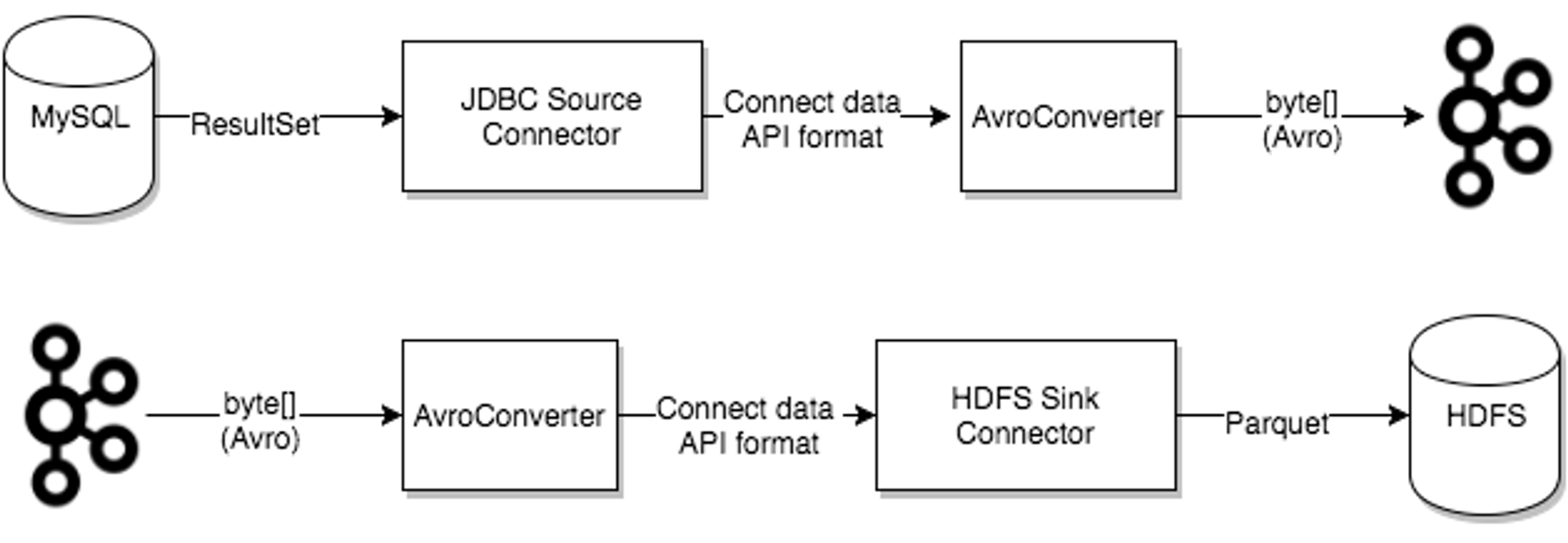
커넥트를 사용하면 서로다른 외부시스템간 데이터싱크를 맞출수 있습니다.
- 이때 Connector라는 일종의 변환장치가 필요합니다.
- 예제에서는 MySQL 에 있는 데이터를 HDFS에 Parquet형식으로 적재하고있습니다.
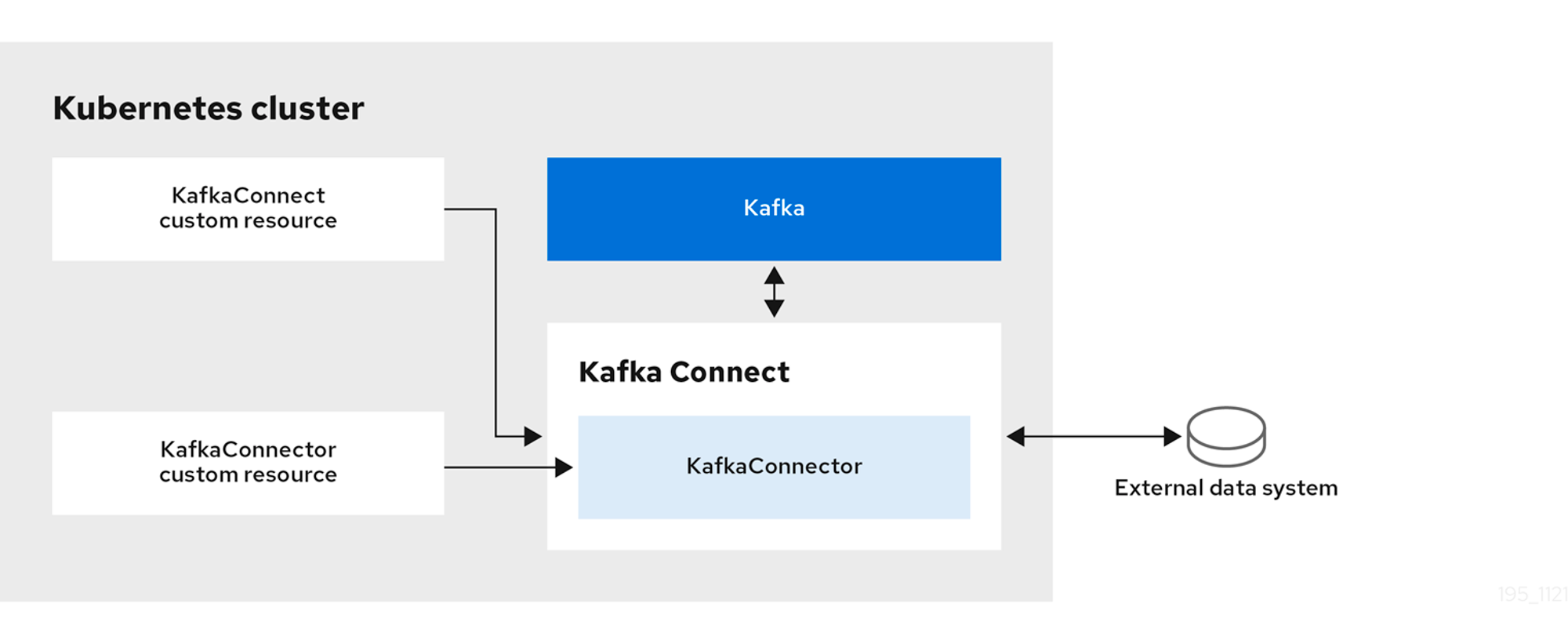
Strimzi에서는 KafkaConnect와 KafkaConnector모두 CR(Custom Resource)로 구성됩니다.
KafkaConnect를 사용해서 외부의 데이터베이스를 Kafka와 연결해서 Data를 연동할 수 있습니다.
카프카 브릿지(Kafka Bridge)
카프카 클러스터와 internal & external HTTP client application을 연동해줍니다.
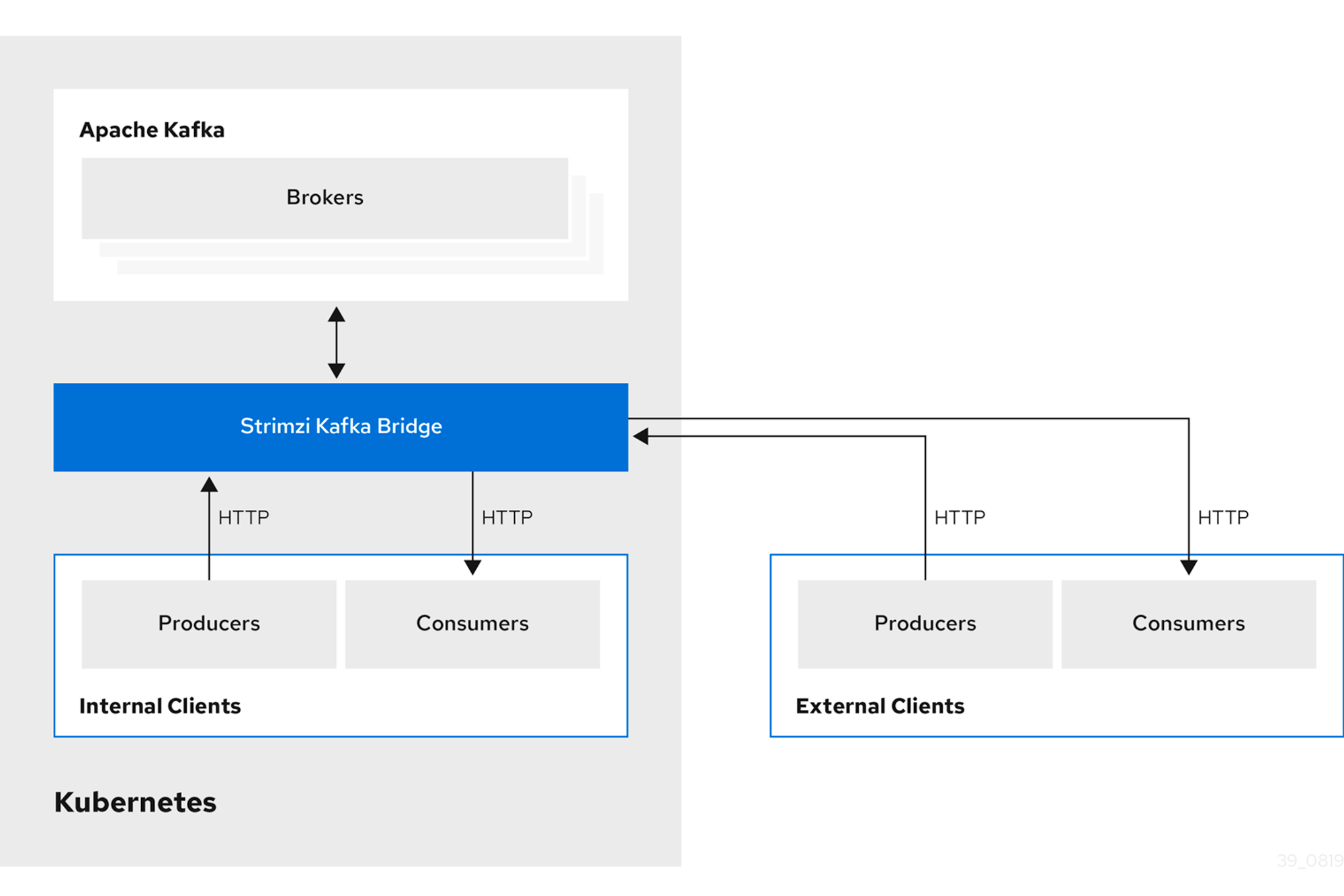
Strimzi에서는 내/외부의 클라이언트(Producer, Consumer)과 통신하여 Broker에 접근하게 합니다.
미러메이커(MirrorMaker2, MM2)
다중 클러스터 환경에서, 클러스터 간 미러링(replication)을 구성합니다.
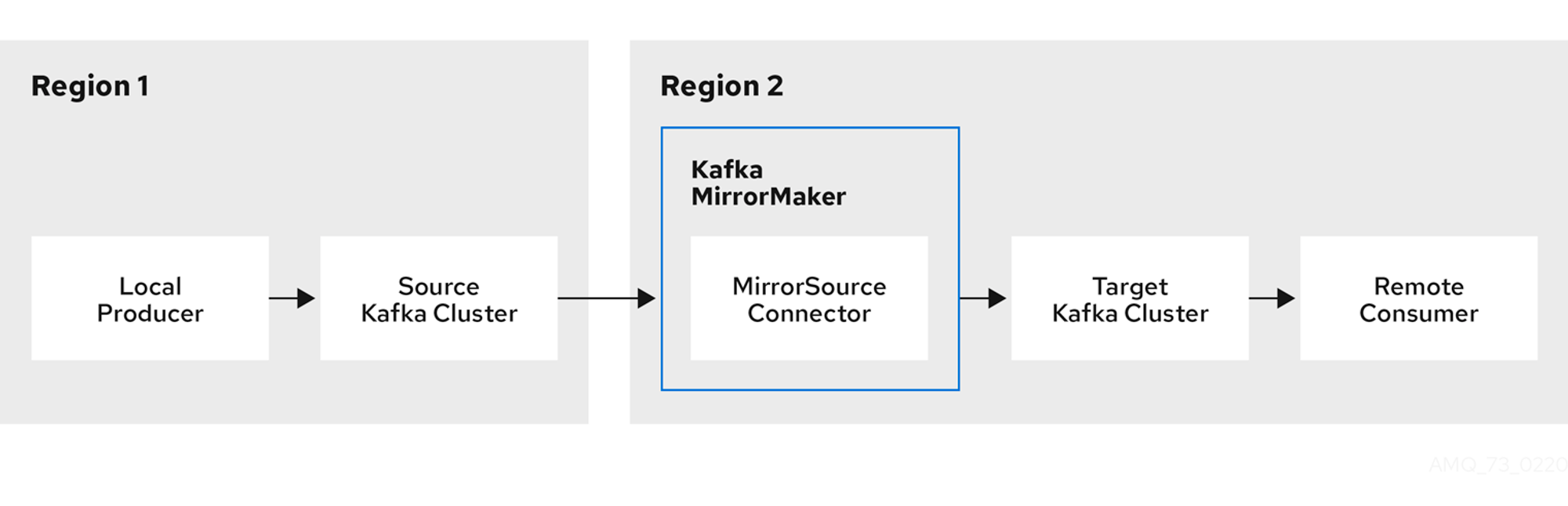
서로다른 Region에 있는 Kafka Cluster를 기준으로
미러링 시킬 클러스터를 Source Kafka Cluster로, 미러링 당할 클러스터를 Target Kafka Cluster로 지정합니다.
- MM2의 장점은 Producer와 Consumer의 Region이 다를때, 카프카 클러스터 간 미러링을 통해서 데이터를 동기화 시킬수 있다는것입니다.
또한 양방향 Topic Replication이 가능합니다.
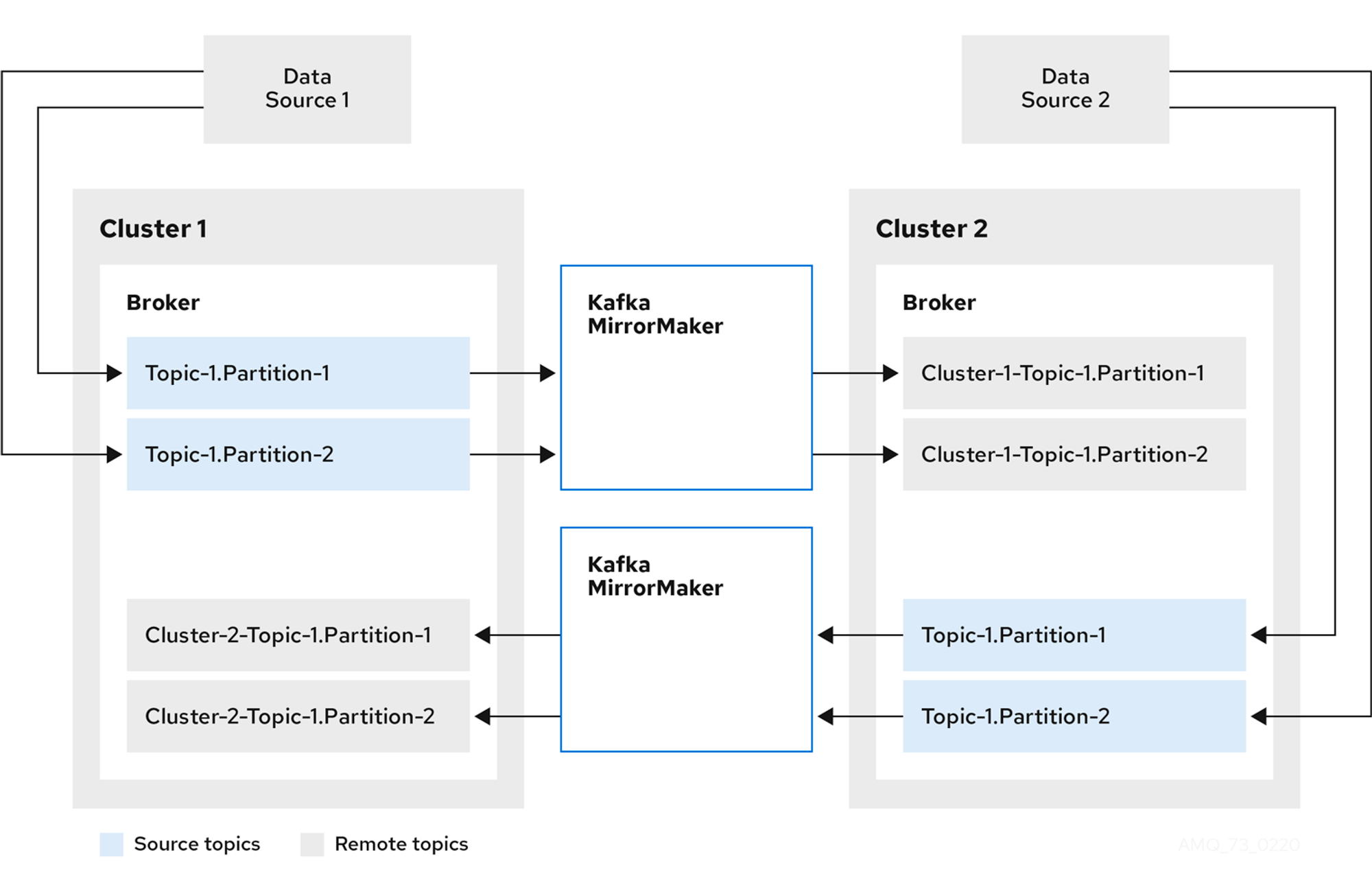
[기존]
클러스터1에 데이터소스1이 연결되어있고, 브로커 내부에 Topic-1로 지정되어있으며, 해당 토픽은 파티션이 2개입니다.
클러스터2에 데이터소스2가 연결되어있고, 브로커 내부에 Topic-1로 지정되어있으며, 해당 토픽은 파티션이 2개입니다.
[미러메이커 진행]
클러스터1의 Topic-1에 대해서 Replication을 진행합니다.
Replication목적지는 Cluster2이고, Cluster2의 브로커에 저장됩니다. 저장될때에는 출발지의 클러스터 이름을 추가해서 Cluster1-Topic1이라고 지정됩니다.
클러스터2의 경우에도 동일하게 적용됩니다.
OUTRO
이번게시글에서는 Apache Kafka의 컴포넌트와 브로커의 동작에 대해서 알아봤습니다. 다음게시글에서 이어서 작성하겠습니다.
'외부활동' 카테고리의 다른 글
| [DOIK2] 스터디: Stackable 로 Airflow 배포하기 + 스터디후기 (3) | 2023.11.26 |
|---|---|
| [DOIK2] 스터디: Strimzi로 Kafka Cluster 배포하기 (0) | 2023.11.18 |
| 구글 클라우드 스터디잼: GenAI 수료후기 (1) | 2023.11.11 |
| [DOIK2] 스터디: Percona Operator for mongoDB (0) | 2023.11.11 |
| [DOIK2] 스터디: GKE에서 CloudNativePG + Promethues + Grafana 연결하기 (0) | 2023.11.05 |