
기존 MapReduce
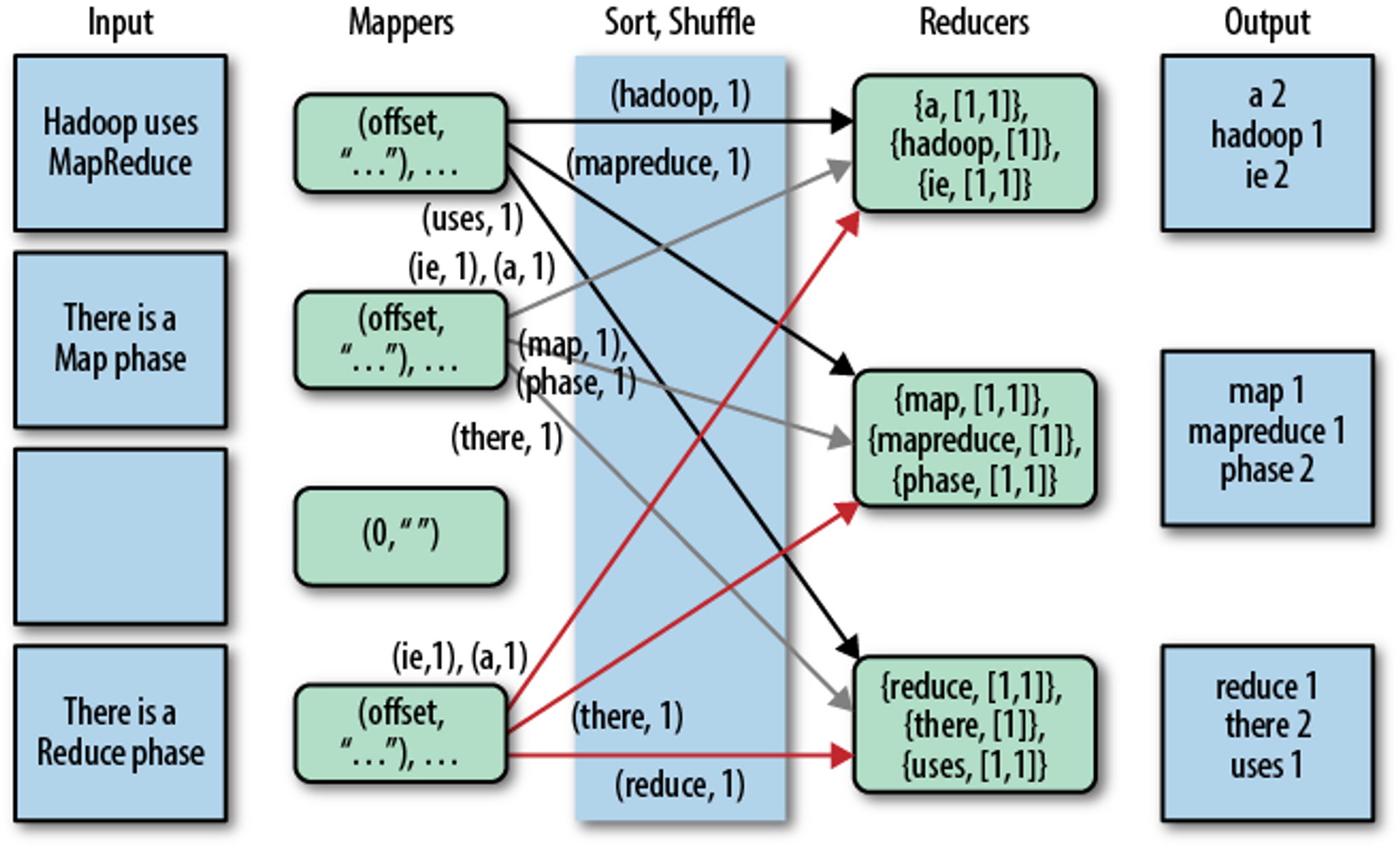
아키텍쳐 : INPUT → Mapper → Shuffle&Sort → Reducers → OUTPUT
- Yarn (MapReduce2)을 사용
튜닝 MapReduce
INPUT → Mapper → Combiner → Partitioner → Shuffle&Sort → Reducer → OUTPUT
- Shuffle & Sort 에서 트래픽이 너무 많이 발생하는데, 이 부분을 줄이는것을 목표로 튜닝을 진행하려고 함
- Mapper, Partitioner에서 나오는 Key를 줄여서, 네트워크 간 트래픽을 최소화 시켜야 한다
튜닝 방법
- 메모리 튜닝
-Xms1024M -Xmx2048M: Java 힙 메모리 조절하기. Xms는 최소, Xmx는 최대 힙메모리 mapred.child.java.opts :램 할당량을 조절할것- IO튜닝HDFS는 write-once-read-many 를 지원한다는것을 이용한것
- checksum, Access시간 등등 체크포인트 옵션이 있을텐데, HDFS에서 이를 비활성화하기
- DISK IO 압축
mapreduce.map.output.compress=true적용하기CPU수치만으로보면 오버헤드가 큰것같지만, Shuffle단계에서 수치를 확 줄일수 있다는것이 장점 - LZO, BZIP, Snazzy 같은 압축기술을 써서 중간데이터 크기를 줄여버리기
- Map output을 줄이는 방법
Reference
'DATA Engineering > Hadoop' 카테고리의 다른 글
| WordCount예제로 보는 Map & Reduce (1) | 2022.11.01 |
|---|---|
| Secondarynamenode(SNN), fsimage, HDFS Balancer (0) | 2022.11.01 |
| Datanode가 죽었을때, Masternode가 죽었을때 (0) | 2022.11.01 |
| 하둡에서 블록 용량 디폴트가 128MB인 이유 (0) | 2022.11.01 |
기존 MapReduce
아키텍쳐 : INPUT → Mapper → Shuffle&Sort → Reducers → OUTPUT
- Yarn (MapReduce2)을 사용
튜닝 MapReduce
INPUT → Mapper → Combiner → Partitioner → Shuffle&Sort → Reducer → OUTPUT
- Shuffle & Sort 에서 트래픽이 너무 많이 발생하는데, 이 부분을 줄이는것을 목표로 튜닝을 진행하려고 함
- Mapper, Partitioner에서 나오는 Key를 줄여서, 네트워크 간 트래픽을 최소화 시켜야 한다
튜닝 방법
- 메모리 튜닝
-Xms1024M -Xmx2048M: Java 힙 메모리 조절하기. Xms는 최소, Xmx는 최대 힙메모리 mapred.child.java.opts :램 할당량을 조절할것- IO튜닝HDFS는 write-once-read-many 를 지원한다는것을 이용한것
- checksum, Access시간 등등 체크포인트 옵션이 있을텐데, HDFS에서 이를 비활성화하기
- DISK IO 압축
mapreduce.map.output.compress=true적용하기CPU수치만으로보면 오버헤드가 큰것같지만, Shuffle단계에서 수치를 확 줄일수 있다는것이 장점 - LZO, BZIP, Snazzy 같은 압축기술을 써서 중간데이터 크기를 줄여버리기
- Map output을 줄이는 방법
Reference
'DATA Engineering > Hadoop' 카테고리의 다른 글
| WordCount예제로 보는 Map & Reduce (1) | 2022.11.01 |
|---|---|
| Secondarynamenode(SNN), fsimage, HDFS Balancer (0) | 2022.11.01 |
| Datanode가 죽었을때, Masternode가 죽었을때 (0) | 2022.11.01 |
| 하둡에서 블록 용량 디폴트가 128MB인 이유 (0) | 2022.11.01 |