
Word Count 예제
흔히 말하는 MapReduce 는 Map태스크와 Reduce태스크로 구성되고, 이를 설명하기 위해 WordCount예제를 들어보려고한다
위 예제는 전체 Input중에 동일한 단어가 몇번이나 나오는지를 확인하는 예제이다
MapReduce의 태스크는 크게 4가지 부분으로 구성된다
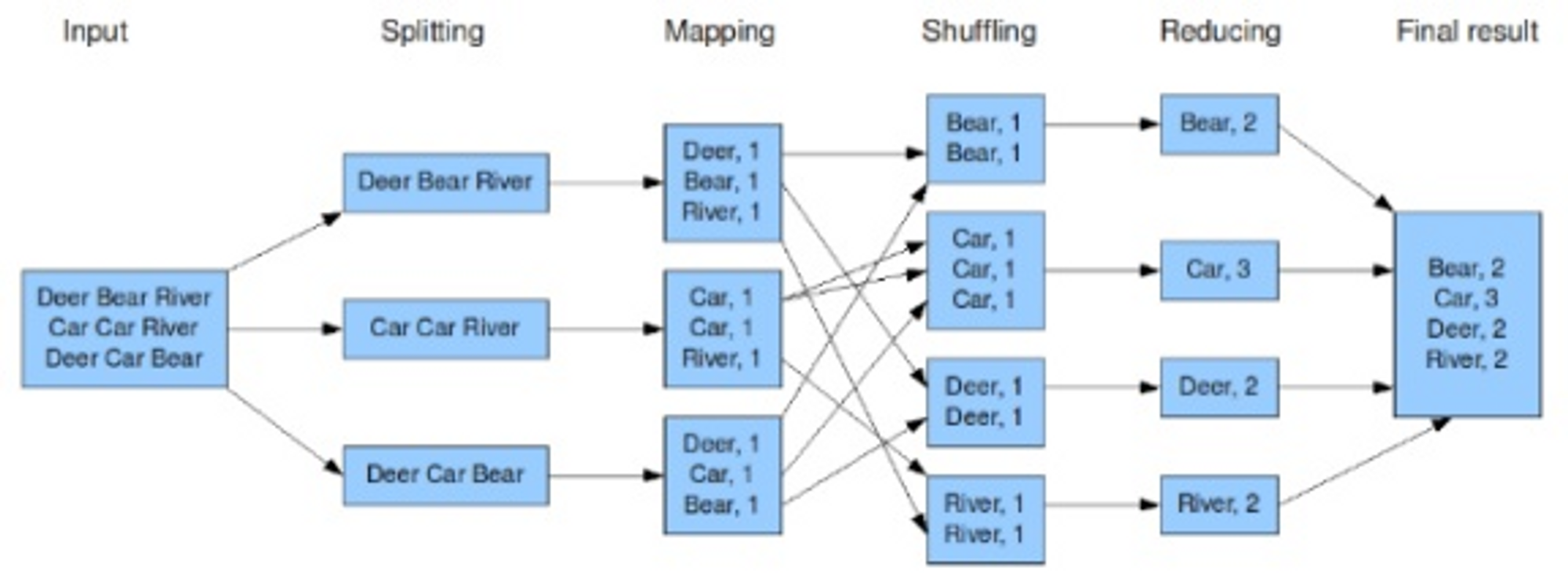
전체는 Spliting, Mapping, Shuffling, Reducing으로 구분되고
그중 Map Task는 Spliting & Mapping
Reduce Task는 Shuffling & Reducing 을 지칭한다
JOB 튜닝
- 블록크기 → namenode heap메모리에 영향받음. 128mb
- replication 갯수 : (복제갯수)일반적으로 3
- CHILD 프로세스 재사용 : Map or Reduce태스크를 실행할때 생기는 독립적인 프로세스. CHILD프로세스는 처리가 완료되면 종료되지만, 재사용을 하게된다면 프로세스 생성과 제거에 드는 시간을 줄일수 있다.
- Reduce시작지점 제어 : 맵단계가 완료된 후 리듀스 단계를 시작하는것보다, 중간에 맵단계에서 임시데이터가 생성될때 리듀스를 진행하는것이 시간적으로 효율적이다. 일반적으로 5% 정도단계에서 하는것이 보편적임
REDUCE 튜닝
MAP Task는 결과를 디스크에 저장하고, Reduce Task가 원격지에 http를 통해 데이터를 복사해간다.
이때 복사를 해가는 Reduce Task의 스레드숫자를 늘리면 빨리 가져갈 수 있다.
핵심은 셔플링을 줄이거나, 셔플링처리속도를 높이는데 있다.
이와 관련된건 Buffer(메모리) 크기가 포인트가 되는데, Buffer의 크기는 java vm에 영향을 준다
MAP REDUCE 튜닝
오피셜적으로는 RAM용량, Datanode에 포함된 디스크 수, CPU코어수, NIC 등의 하드웨어 사양에 영향을 받을거임
근데도 굳이 서비스적으로 해결하려면 두가지 정도가 있다
- Runtime Parameter Tuning
- 메모리 튜닝
- input records, reducer records, pipelined records, swap memory, heap memory 등의 정보를 수집한다
- 일반적으로 CPU에 영향을 받지않으며, memory사용 및 Disk최적화와 연관있다
- MapReduce작업이 swapping을 하지 않는 한에서, 메모리를 최대한으로 주는것이 최고다
- 스왑메모리 사용률이 높을때마다 각 작업에 할당된 RAM사용량을 줄이기
- Map Disk Spill 최소화
- DISK IO는 하둡 내에서 BottleNeck을 가져오는데
- Spilling을 최소화 하는것이 제일 좋음
- Mapper가 Map작업을 하면 쌍이 나오는데, 얘를 HDFS에 저장하지않고, RAM에다가 저장함. (기본값 100메가). 메모리버퍼에서 DISC로 데이터를 가져갈때 Spilling(누출) 이 되는데, Buffer사이즈가 Threshold size(임계값) 에 다다랐을즈음에 발생함. 일반적으로 버퍼사이즈의 80%정도가 차기 시작할때부터 Spilling(누출) 이 된다고 본다.
- Mapper Task 튜닝
- 각각의 Mapper Task의 job 전체를 최적화 하는것도 중요한데
- Jvm task를 Reuse한다던가
- Mapper 실행시간을 늘려서, 더 적은 Mapper가 reinializing 되지않게한다(재실행시 오버헤드를 줄인다)
- 메모리 튜닝
- Hadoop Aplication Tuning
- Mapper Output Minimizing
- Mapper Output은 DISK IO, NETWORK IO에 영향이 있는데
- Reducer대신 Mapper쪽에서 레코드를 필터링한다던가
- Mapper 출력 전체를 줄인다던가
- Balancing Reducer Loading
- 얘가 로드벨런서인가 ?
- reduce task의 unbalanced(양이 서로 다른거)는 성능이슈가 있는데 이 부분을 정하는것
- Partitioner class를 고르는 더 나은 Hash Function을 고르는것
- Key를 전처리해서, 많은 결과로 나오는것을 방지하는것
- Combiner를 사용해서 하둡클러스터의 성능 자체를 올리는것
- Mapper Output Minimizing
참고자료
https://techvidvan.com/tutorials/hadoop-mapreduce-performance-tuning/
'DATA Engineering > Hadoop' 카테고리의 다른 글
| MapReduce 튜닝하기 (0) | 2022.11.01 |
|---|---|
| Secondarynamenode(SNN), fsimage, HDFS Balancer (0) | 2022.11.01 |
| Datanode가 죽었을때, Masternode가 죽었을때 (0) | 2022.11.01 |
| 하둡에서 블록 용량 디폴트가 128MB인 이유 (0) | 2022.11.01 |