
주된 차별점
- 2Stage Model
- Multiple Ranking Objective
- Multitask
- Implicit Feedback ( feedback loop )
- Bias ( Selection Bias == Position Bias )
어떻게 추천할 것인가?
(예시상황)
사람들이 Video platform에서 Video를 계속해서 시청하고있는 상황.
나는 User가 platform에서 더 많은 동영상을 보고, 더 많은 시간을 사용하게하고싶음
→ User가 좋아할만한 동영상을 추천해주자
⇒ '다음동영상'으로 어떤 동영상을 추천해줄 것인가? 에 대한 문제로 귀결됨
그렇다면 무슨 기준으로 추천을 해야할까?
크게 생각했을때는 2가지 기준으로 나눌것이다.
- 일반적으로 사람들이 좋아하는 부류의 동영상을 추천해주기
- 내가 좋아하는 부류의 동영상을 추천해주기
Youtube의 기본화면을 봐보자
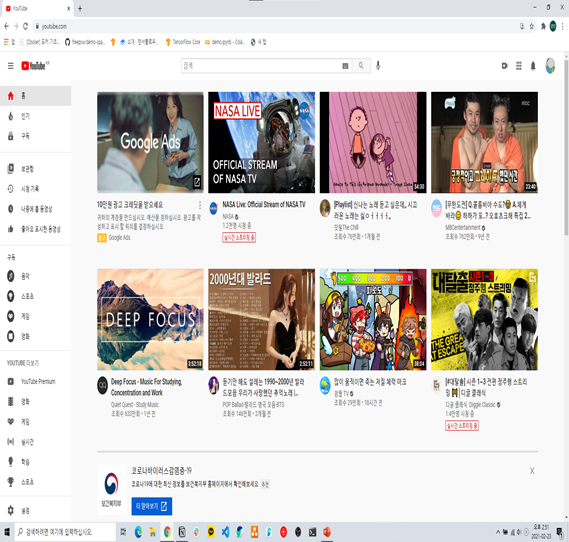
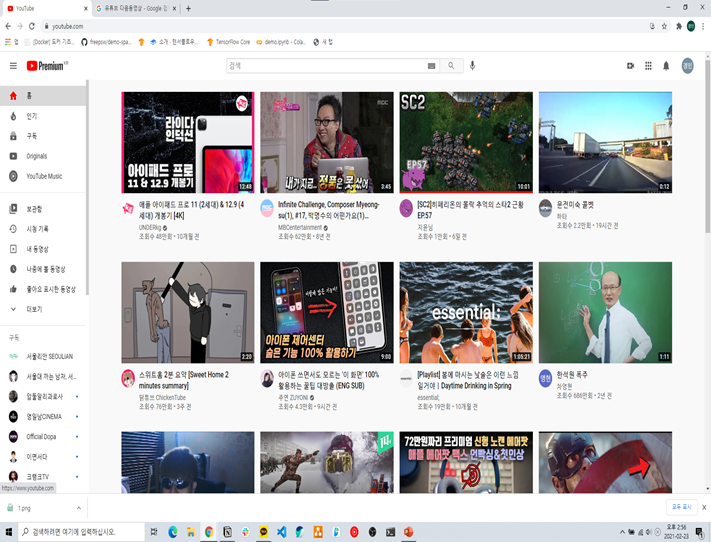
(좌)처음유튜브에 들어가본 계정 : 일반적으로 사람들이 좋아하는 부류의 동영상 이 많이 보이는반면,
(우)평소에 사용하는 계정 : 내가 좋아하는 부류의 동영상 이 많이 보이는것을 알수있다
동영상을 직접 눌러서 봐보자
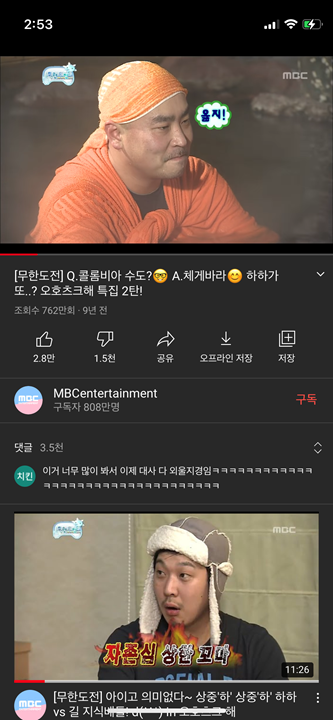
이 경우에는 무한도전에서 '자존심이 상한 꼬마' 라는 썸네일을 가지는 동영상이 유저에게 추천된 경우이다.
시청중인 동영상(무한도전)과 비슷한 동영상(무한도전)이 추천동영상으로써, 댓글창 하단에 위치해있다.
이는, 시청중인 동영상(무한도전)을 'User가 직접 선택했으니' 이 동영상은 'User가 관심있어하는 동영상 일것이다' 라고 생각했고
이를 기반으로 '지금 시청중인 동영상과 비슷한 동영상'을 User에게 보여주면 User도 좋아할것이다. 라는 생각을 기반으로 비슷한 동영상이 추천된것이다.
⇒ 즉, Youtube는 지금 시청중인 동영상을 기준으로 비슷한 동영상을 User에게 추천해준다.
0. Abstract
User가 Video를 선택할때 'User의 주관'이 개입함 ( User는 자기가 보고싶은 동영상을 봄 == '주관')
User가 추천된동영상을 선택하고, 검색창에 검색하고, 동영상들을 시청하고, 다른 동영상을 검색하는행위 ⇒ Implicit Data ⇒ Implicit Feedback (bias)
GOAL : Feedback문제를 해결하기
- Multiple ranking object를 고르는 soft parameter sharing technique
- Wide&Deep framework 를 기반으로 하는 Bias감소방법
1. Introduction
Model Stage구성
Model
Layer1 : Candidate Generation Layer
Layer2 : Ranking Layer
(이 논문은 Ranking Layer에 focusing한 논문)
Layer1에서 Candidates Objectives를 만들고(후보동영상을 만드는과정)
Layer2에서 Dandidate를 대상으로 Ranking모델을 적용함(후보동영상들을 1위~200위까지 줄세움)
→ 후보동영상은 User가 선호하는 순서대로 나열됨
Video시스템을 구축하기위해서 해결해야 할 문제1
선택지가 多인 상황
User가 Video 시청을 다 했음
- 추천선택지1 : 다른 동영상을 시청하기
- 추천선택지2 : 지금 본 동영상을 친구에게 추천해주기
→ 이런상황에서 어떤 선택지를 할것인가??
Video시스템을 구축하기위해서 해결해야 할 문제2
Feedback loop상황
User는 동영상이 'User가 관심있어했던 동영상' or '흥미가 없는 동영상' or '새롭게 흥미가 생기는 동영상'을 시청할수 있음.
근데, 동영상을 선택했을때 유저가 선택한동영상과 비슷한 동영상을 추천해주는 시스템을 채용하고있으니,
User가 흥미가없는 동영상을 시청했을때(User가 싫어하는 동영상)
User에게 추천되는 동영상도 User가 싫어할 것이다. 라는게 Feedback loop이다.
Model Architecture
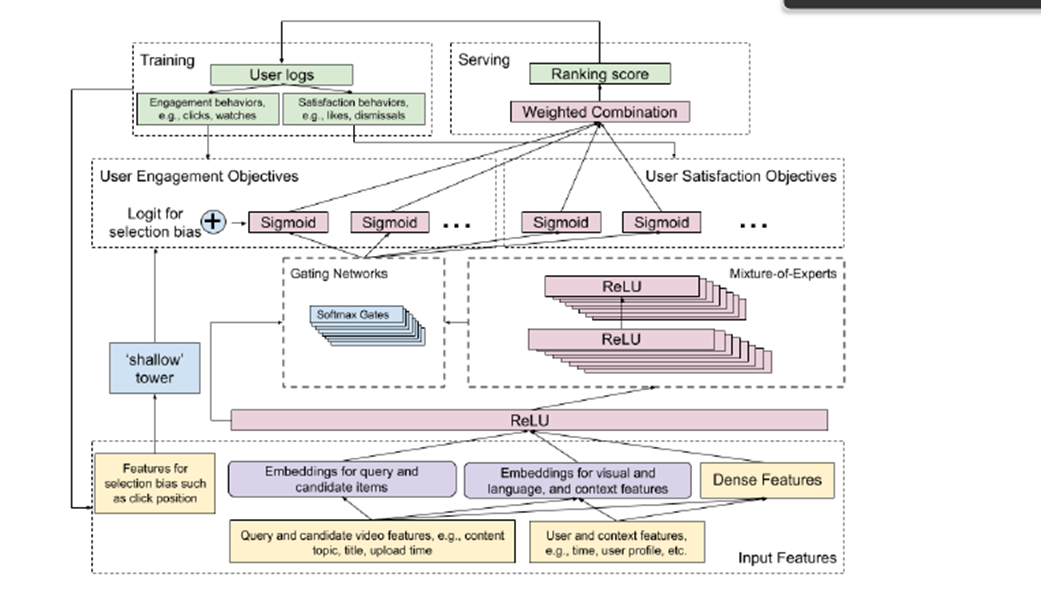
주요하게 볼 내용
- Input Feature가 2개로 나뉜다(보라색)
- Query and Candidate itmes
- Visual and language and context features
- 주요모델은 2가지로 구성
- 왼쪽의 shallow tower
- 오른쪽의 main tower
- Objectives가 2가지로 구성
- User Engagement
- User Satisfaction Objectives
- Serving할때 Ranking score가 나온다는거
- Traning에서 User logs는 2가지로 구성
- Engagement behaviors
- Satisfaction behaviors
2. 주요모델
- 왼쪽의 shallow tower : ranking selecton bias를 조절하는역할
- 오른쪽의 main tower : MMoE : User의 Action을 예측하는역할
MoE ( Mixture of Experts)
- MMoE ( Multigate Mixture of Experts) : MMoE에서 User의 Action(참여, 만족도) 을 예측함
- Multitask Learning 을 위해서, 기존 Wide&Deep Model에 MMoE개념을 추가한것이라고 봐야함
User log
User가 행동했던 모든 것들이 Log임 (Multiple Objective)
- User가 직접 참여하는 종류의 Log
- User가 동영상을 클릭하는 행위
- 추천된 동영상을 User가 보는 행위
- User가 동영상에 만족하는 종류의 Log
- 영상에 대하여 좋아요를 누르는 행위
- 영상을 보는중에, 영상을 그만보는 행위
→ 1과 2에 중복되는 Log가 존재할수 있음
(User가 직접 참여하면서 && User가 동영상에 만족하는행위)
⇒ Shallow tower로 해결함
Gating networks + MMoE
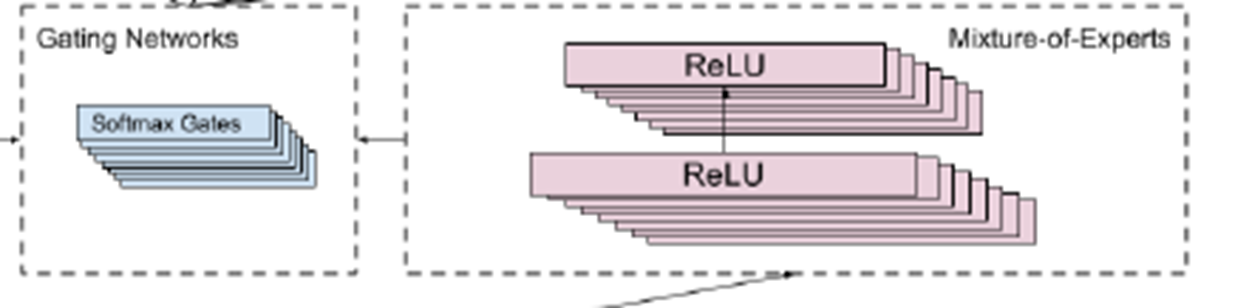
MoE는 Input layer를 Expert로 모듈화 시키고, Layer 마다 Input의 서로 다른 부분을 받는다.
: 2가지로 나뉜 Object는 Input Layer의 서로다른 모듈로 들어간다.
이런식으로 input을 받으면 Object에 대한 현상을좀더 객관화시킬수있음
Multiple Gating Networks를 통해서 Object마다 experts를 선택하여 다른사용자과 공유하거나, 공유하지않을수 있음
Input features
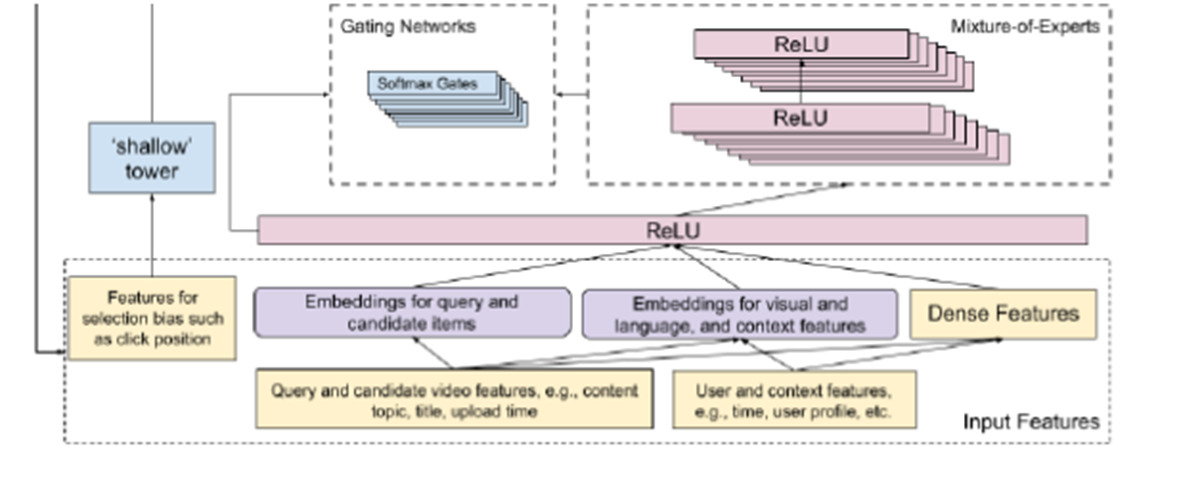
input features(training data)를 2개의 부분으로 나눈다.
main model부분에서 학습되었으나, unbiased된 user utility
shallow tower에서 학습된, estimated된 propensity score
Shallow Tower
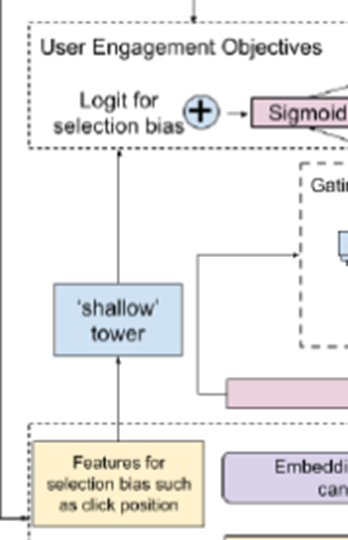
input features에서 selection bias(ex. position bias)를 modeling하고 reduce하기위해서 존재함.
input으로는 selection bias와 관련된 것(ex. ranking순위) 들을 받고
output으로는 scalar를 도출한다.(이때의 scalar는 최종예측에 큰 영향을 주는 bias이다)
Model Architecture구성이 가지는 의미
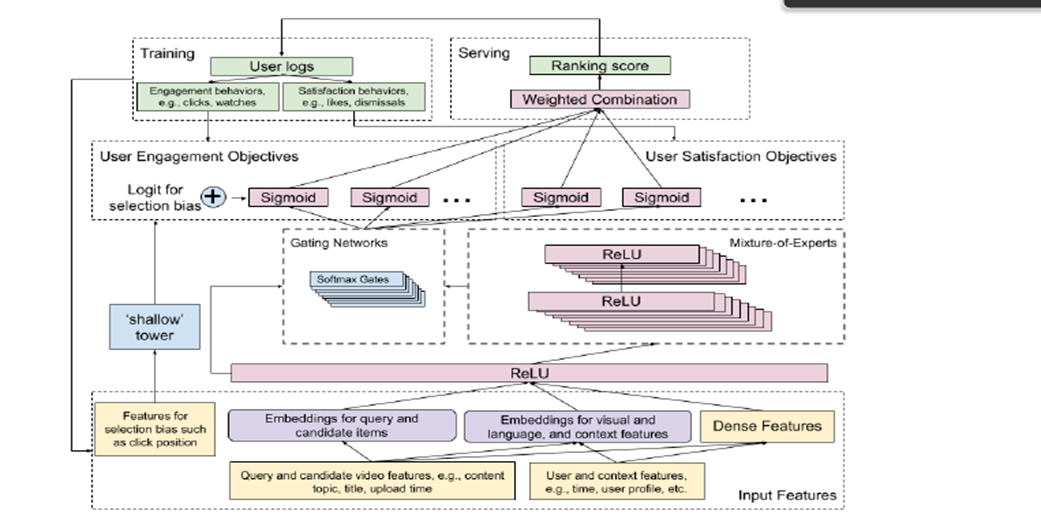
이러한 전체모델구성은(main model + shallow tower)
Wide &Deep모델의 확장으로도 볼수있을것이고
shallow tower가 Wide부분을 맡는다고 보면된다.
이러한 내용을 통해서 propensity score를 얻기위해 무작위 실험에 의존하지않고,
selection bias를 학습하는 이점을 가진다.
Architecture의 효과를 검증하기위해 Multitask learning Removing a common type of selection bias(e.g. position bias) 해당 내용에 대해서 offline과 LIVE실험을 진행하였음
End to End + Ranking
1. Ranking 문제를 multi-objective learning로 공식화
2. MMoE로의 확장
3. Wide & Deep 모델의 확장
4. position bias의 문제를 해결하는것
5. real world scale의 video recommendtaion시스템에 적용했다는것에 의의를 가진다.
2. Related Work : Query
Recommendation == high utility item반환하는 문제 (이때 사용하는 User log는 User의 Histroy가 사용됨)
e.g User가 Friday night에 tablet으로 home에서 movies를 봤다면?
Who : User
Time : Friday night
Device : tablet
Where : Home
What : movies
이런식으로 Query를 구성할수 있음
2.1 Industrial Recommendation Systems : Explicit or Implicit여부
Training Dataset의 부족 (Implicit Data만 사용함) → explicit feedback으로 해결하려고했음
현실적으로는 explicit feedback의 경우 비용때문에 실행하기는 어려움
→ click이나, 추천된 items를 보는것에 참여하는 User의 참여형태로 존재하는 implicit feedback 를 사용한다.
2.2 Multi-Objective Learning for Recommendation Systems
해결해야할 문제 : 동영상을 클릭해서 봤지만, User 마음에 들지않는경우
→ 클릭된 video에만 점수매길수있는 시스템특성상 마음에들지않은 Video에도 Score를 줄수밖에없음
⇒ 싫어하는 Video가 계속 추천되는 상황이 발생함
해결방안
User behavior + utilities의 결합 → User behavior를 Train & Estimate
→ 결과를 Combine → Final utility score를 계산함 ⇒ Ranking(줄세우기)
기존모델의 단점
- CF or CB의 user-item 유사도를 확장한 모델
- 기존모델은 Candidate generation단계에서는 매우 효과적이지만
- DNN을 사용한 ranking모델과 비교했을때 Final recommendtaion에서 덜효과적임
- Text or Vision을 대상으로 하는 Multi Objectie Ranking모델
- 기존모델을 유튜브썸네일이나 이런곳에는 사용하기 좋겠지만
- sharing model parameter를 효과적으로 처리하지못해서 비효율적
2.3 Understanding and Modeling Biases in Training Data : Feedback & Feedback
Training Data로 사용하는 User behavior → User feedback(User log)
→ User behavior는 selection biases를 제거해야하는 목표가 생김
Current System에서 가장 Video를 1~10위까지 추천해주었는데, User가 1순위 video를 선택했을때
→ 이 경우에도 feedback이 발생함
( click data와 explitcit feedback을 비교했봤는데. click data에 position bias가 존재하고, QUERY와 DOCUMENTS 사이에서 position bias(selection bias)가 문제를 일으키기에 [23,34,31]에서 제거를 하려는 시도를 했었음)
Selection Bias를제거하는법
Model
1. input feature로 position을 inject +model을 traning
2. serving할때 bias를 제거하여서 사용함
Probablistic click Model
: P(relavance | pos) == 추천된 위치당, 선택될 확률
CTR Model
P(relavance | pos)
→ position이 1일때, 평가에 대한 position bias가 0 이된다는것을 사용함
⇒ position bias를 제거하기위해서, input feautre로 position정보를 사용 && position feature 값을 1로 설정(혹은, missing value나 다른수치로 고정)
3. Problem Description
우리의 모델 : 2stage Architecture
1Layer : Candidate Generation
2Layer : Ranking
Ranking 시스템에서 생기는 문제들
☆Multimodal feature space
☆Scalability
Multimodal feature space
조건 : Context-aware personalized RS
목표 : multiple modalities 기반으로 -> User utility를 도출해내야함
이유 : Multimodal feature space에서 라는 특징때문
도출하는 것들
- Low level content로 부터 semantic 격차를 해소함 (Content filering를 잘하기위하려는 목적)
- item의 분포가 sparse distribution인 상황에서의 learning (Collaborative filtering에서 사용하려는 목적)
Scalability
기반 : Youtube
특징1 : 수십억명의 User + 매우多동영상의 플랫폼
→ Ranking 시스템에서 하나의 Query가 수백개의 Candidate’s score에 영향을 줌
특징2 : Real-world scenario
→ 일부 Query와 Context 정보는 Online단계에서만 사용가능함
→ 모델은 서비스를 제공(serving)하는 동시에 items과 users에 대한 학습을 진행할수 있어야함
Paper's goal
상황 : 현재 User가 Video && Context를 보고있는 상태에서 ranked list of video를 제공
목표 : multimodal feature space 정제 방법 :
- Video -> ( Video meta data + Video Content Signal)
- Context -> (user demographics + device + time + location …)
- Candidate generation stage :huge corpus로부터 a few hundred candidate를 검색하고(뽑아내고)
- Ranking stage :Candidate들에게 score를 기반으로 하는 ranked list를 제공
3.1 Candidate Generation : Multiple candidate generation algorithm
stage1 : Multiple candidate generation algorithm 사용
→ 각각의 algorithm은 Query video와 Candidate video의 유사성의 일부분을 capture 하는역할을 함
논문에서 User log(History)를 사용하기위한 sequence 특성
(Context-aware high recall relevant candidate를 하는 특성)
⇒ Stage1의 마지막에서는 모든 Candidates가 하나의 set으로 풀링 && 그 후에 순위 체계에 의해서 Score화
*Multiple candidate generation algorithm?
- 하나의 알고리즘이 Query video의 topic을 matching시켜서 candidate video를 만들고
- 또다른 알고리즘이 Query video와 함께 video를 시청한 빈도를 기준으로 Candidate video를 검색하는 방식
3.2 Ranking
input : Stage1에서 output으로 보내주는 Candidate set
Output : User가 좋아할만한 ranked list itmes (item utility)
4. Model Architecture
다룰 내용은 3부분임
- Multi objective setup: multiple types of user behaviors를 학습하기위함
- state-of-the-art multitask learning model architecture: 적용 및 확장
- MMOE && shallow tower를 통해서 training를 진행하고, 이때 생기는 selection bias(position bias)를 제거하는 방법에 대한 설명
4.1 System Overview : Ranking → Multiple Objective
Stage2의 input : Candidate의 feature(Query and context)
Stage2의 goal : User가 어떻게 행동하는지 predict 하는법을 학습
Learning to rank framework를 적용 -> Stage2의 Ranking problem을 Multiple objectives를 가지는 Classification문제 && Regression문제로 바꿨다.
Training Data : User feedback의 종류
- User가 참여하는 행동(e.g. 비디오를 Click & Watch)
- User의 만족도 행동(e.g. 비디오에 대해서 LIKE버튼을 누르는 행동)
User feedback 을 기반으로 Stage1에서 Candidate가 도출됨
Stage2에서는 Stage1의 Candidate의 feature기반으로 User behavior를 예측하는 방법을학습함
Point-wise vs Pair-wise, List-wise
Pair-wise or List-wise 방법 :
Multiple candidates에 대해서 prediction하는 방법을 Train가능함 (->multiple candidates로부터 Recommendation의 diversity 확장가능) Candidates의 조합에 대해서, Scoring하는 과정이 많기때문에 확장성의 제한이 있음
Point-wise
1. Serving할때 simple && large scale에 efficient 하다는 특징
2. Point-wise방법사용
4.2 Ranking Objectives
Training Label로 사용하는것 : User behaviors
추천되는 recommended items 에 대해서, User는 多동작을 할수있음
→ Multiple objectives로 나눌 수 있음
1개의 Objective당, 1개의 user utility만을 prediction에 사용
Objectives 를
- Engagement Objectives와
- Satisfaction Objectives로 구분함
Engagement Objective-> Binary Classification + Regression
Engagement Objective ==Binary Classification+ Regression
Binary classification task (e.g. 동영상, 좋아요 버튼의 클릭여부)
Regression task (동영상을 보는데에 대한 시간을 얼마나 사용하였는지)
Loss 사용 : Binary classification task : cross entropy loss Regression task : squared loss (e.g.MSE)
4.3 Modeling Task Relations and Conflicts with Multi-gate Mixture-of-Experts
일반적인 shared bottom 구조 사용시Multiple objectives에 대한 Conflicts(충돌)문제가 생김
→ MMoE를 사용해서 해결
MMoE (Multi-gate Mixture of Experts)
soft-parameter sharing model structure : task conflicts && relations를 모델화하기 위함
MoE를 모든 task에 대해서 공유하고, 각각의 task에 대해서 gating network를 훈련시킨다
⇒ MoE구조를 Multitask learning화 시킨다 :: MMoE
일반적인 Multiple objective를 사용하는 Ranking system : shared bottom Layer의 구성
그러나 이런식의 hard-parameter sharing기술은 task간의 Correlation(상관관계)가 낮을때 Multiple objectives에 대해서 충돌문제가 생길수도있음
MOE
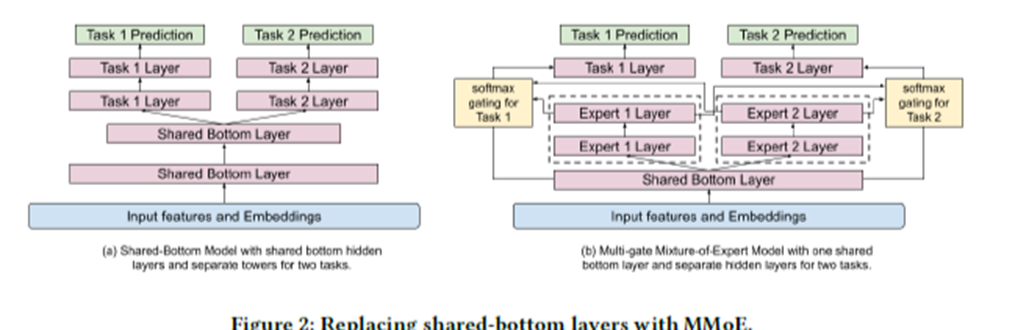
Expert Layer
→ Modularized된 information으로부터 Learning에 도움을 줌 ⇒ Input Layer또는 Hidden layer에서 Multi modal feature space구현에 도움됨
왼쪽(기존) 오른쪽(MMoE) 의 차이
Shared bottom layer 1개 && Task Layer 1개 -> Expert Layer 2개로 바꿨음
주의점
MoE를 input Layer에다가 적용시 model traning && serving 할때 Cost가 증가한다는 단점이 있고 (이유 : Input Layer의 차원이 hidden layer보다 고차원이기때문)
4.4 Modeling and Removing Position and Selection Biases
Implicit feedback 기존방식 : rank model에서 learning을 train하기위해서 사용
매우많은 양의 User logs로부터 추출된 Implicit feedback은 복잡한 DNN 기반 모델을 train시킬수 있음
※ implicit feedback은 현재 존재하는 ranking system에 의해서 생성되었다는 것 때문에 편향(biased)되었다는걸 알아둬야함 (의역 : Data를 뽑아내는 유튜브의 경우. 어쨋든 유튜브 자체도 ranking system에 의해서 만들어진 프레임이기떄문에, 여기서 뽑아내는 Data가 순수한 Data가 아니라, 편향되었다는것을 알아두어야한다)
Selection Bias(Position bias)
일반적으로 사용자는
- 상단에 추천된 Video의 user utility와 이전에봤던 video의 연관성과 상관없이, 상단에 추천된 Video를 클릭하고 시청하는 경향이 존재함
→ 목적 : 이러한 Position bias를 제거해줘야함
Traning data의 selection bias를 제거하고 모델링
→ Model의 퀄리티 상승 && selection bias에서 생성되는 feedback loop를 break시킬수있음
※ User는 상단에 있는 영상이 내가 좋아할만한것, 내가 좋아하지않을만한 것이여도 무조건적으로 상단의 영상을 클릭하고 시청하는 경향이 발견되었음
Model = main tower + shallow tower
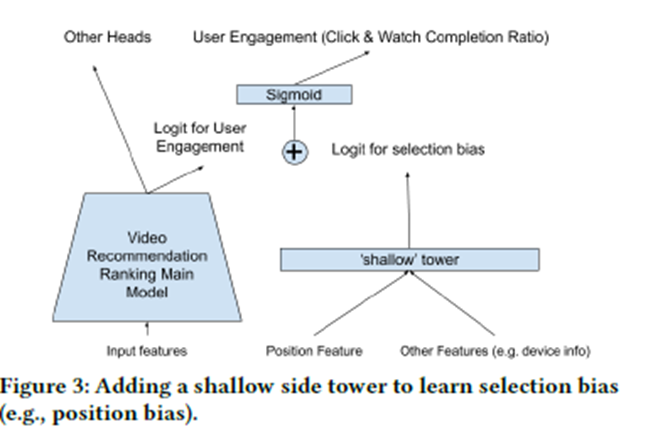
Model Architecture에서
a user utility component->(main tower)
bias component -> (shallow tower)
Shallow tower 구성하는 이유
Train할때
- 모든 impressions의 positions값이 사용되고
- 10%의 feature drop-out rate를 설정→ position feature에 Overfitting을 방지함
Serving할때
- position feature는 사용하지않는다.
※ Serving할때 position feature를 사용하지않는이유 (position feature와 device feature를 교차전달해주지않는이유 ) : devices의 different types의 different position bias가 관측되기 때문이다.
5. Experiment results
실제 실험 : Youtube
Implicit feedback + Offline expertment +Live experiments
Implicit feedback을 사용하여, ranking model을 train할것이고,
offline experiments와 live experiments로 test를 진행함
실험대상이 Youtube 인 이유 :
거대한 규모와 복잡성을 가지고있음 : testbed로 사용하기에 좋음
User가 recommended results와 상호작용을 하는 user activities가 무지막지하게나옴
next video를 추천해줌
User interaction : click, watch, like, dismissal 같은 선택지가 존재함
Offline experiment
Classfication task에 대한 AUC && Regression task에 대한 squared error를 구한다.
Live experiment
A/B Test를 진행함
A/B Test
원인과 결과를 찾는 테스트 e.g. 물놀이 익사사고랑 아이스크림 가격의 연관성
→ 물놀이하는곳 근처에 아이스크림을 팔고있으니 아이스크림 가격을 올리면, 사람들이 물놀이하러 덜 갈것이고 그러면 자연스레 익사사고 수가 줄어들것이다…
Offline실험과 Live실험은 learning rate같은 hyper parameter로 조정해서 사용한다
Youtube == Realtime application
과거~현재 Data : Model train에사용 현재Data ~ing : 지속적으로 training → 가장 최근의 Data에 적응함
5.2.1 Baseline Methods
Baseline method :
- shared-bottom model architecture (Figure 2a)
Model complexity : (복잡성)
- Multiplication in Model architecture -> Effeciency 小
⇒ MMoE Layer는 Input layer보다 lower dimensionality를 사용하는 bottom hidden layer를 공유한다(Figure 2b)
5.2.2 Live Experiment Results
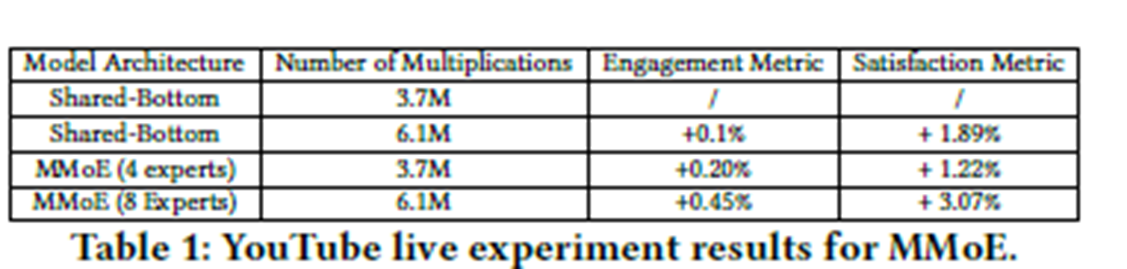
5.2.3 Gating Network Distribution
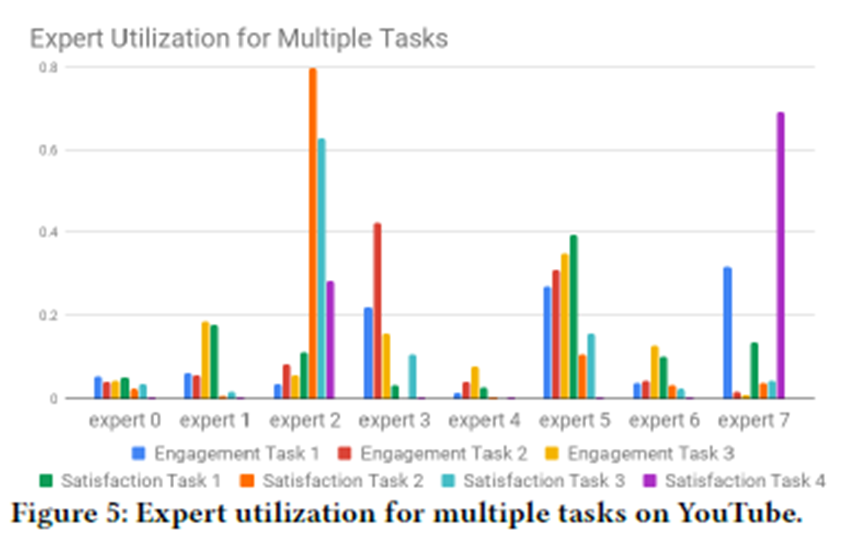
5.2.4 Gating Network Stablity
MMoE에서 softmax gating networks가 가지는 문제 Imbalanced expert distribution problem (불균형)
불균형문제-> Gating network의 polarization발생 (model performance에 악영향)
해결책으로 Gating network에 drop-out을 적용해서 Polarization을 제거함
5.3 Modeling and ReducingPosition Bias
Input으로 사용하는 Data : User feedback
Implicit feedback 와 true user utility에 대한 차이를 제거해야함
→ 경량화된 모델을 사용하여서 SelectionBias를 모델링하고
→ 줄이는 방법을 사용하였음
5.3.1 Analysis of User Implicit Feedback
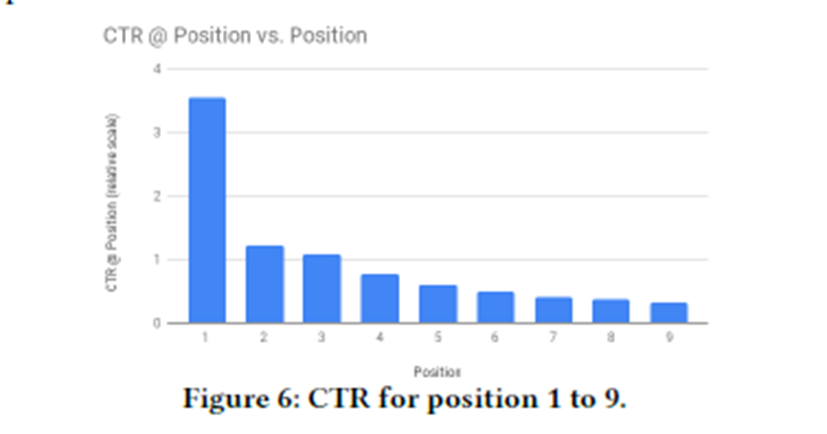
위치별 클릭률을 비교 1(상단)~9(하단)
상단의 item 클릭률이 압도적으로 높다
CTR : Click thourh rates 클릭률
상단의 CTR이 높은 이유:
더 관련성이 높은 항목 && Position Bias 때문
Shallow Tower를 사용해서
Position bias가 제안된 접근 방식을 사용하여 User Utility 와 Position Bias의 분리를 입증함
5.3.2 Baseline Methods
Directly using position feature as an input feature : Position 값 자체를 input feature라고 사용하는것
Adversarial learning : Traning Data의 position을 예측하는 단계를 도입
→ 이후 back propagation phase에서 Grdient를 반대로줘서, Model의 prediction이 position feature에 영향을 받지않게함
5.3.3 Live Experiment Results
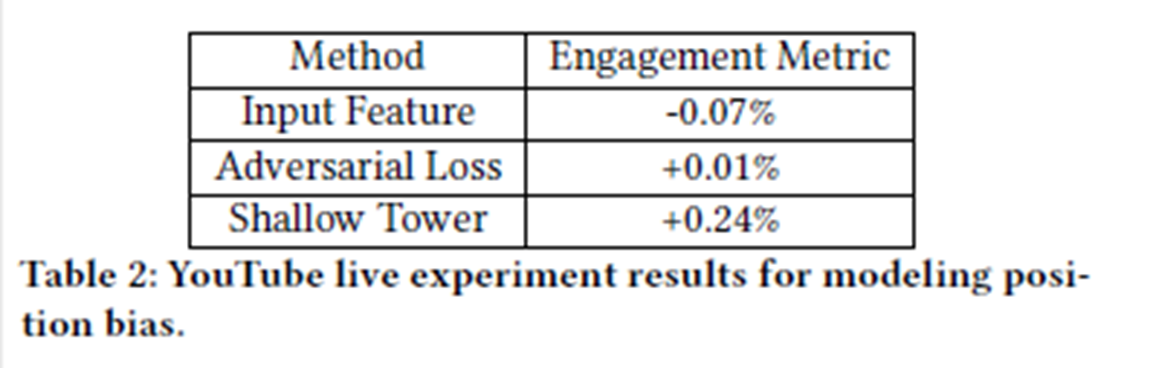
Position Bias를 모델링해서 실험해봤더니 Engagement Metirc이 향상됨
5.3.4 Learned Position Biases
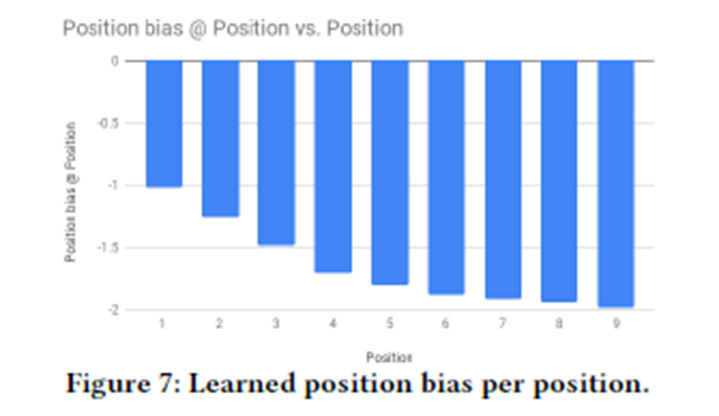
5.4.1 Neural Network Model Architecture for Recommendation and Ranking
- Multimodal feature spaces.
- Query의 내용, item, context 같은 다양한 feature
- Scalability and multiple ranking objectives
- 다양한 Objectvies에 동시에 적용하기 힘듬
- Noisy and locally sparse training data.
- 대부분의 희소기능은 사용량이 적음 → embedding space 를 최적화 하는것에 어려움이 있음 (ex. Longtail. 80:20분포)
- Distributed training with mini-batch stochastic gradient descent
- 대규모의 신경망 모델을 사용해야함 -> Data가 많기때문에 분산학습을 진행해야함
5.4.2 Tradeoff between Effectiveness and Efficiency.
효과가 매우높은모델(유저가 매우 좋아할만한 item을 뽑는것) → Cost소모가 크고, Time이 오래걸린다 → User가 싫어함
⇒효율성에도 신경써야함
5.4.3 Biases in Training Data
Position Bias : 현재논문에서 가장 문제로 삼고있는 Bias
But. 논문에서 밝히지 못한 Bias가 더 있을것이라고 판단하였음 (아직은 모름)
5.4.4 Evaluation Challenge
Test는 Offline test + Live test 로 진행함 (즉, Offline test의 성능이 Live test의 성능에 바로적용되지 않음)
→ 더욱 더 simple한 모델이 필요하다고 판단함
5.4.5 Future Directions
앞으로의 Ranking system의 방향성
Exploring new model architecture for multi-objective ranking which balances stability, trainability and expressiveness.
Understanding and learning to factorize.
Model compression.
6. Conclusion
Training Data의 User implicit feedback이 문제점이였고
특히 Position Bias가 문제였음
→ 해결하기위해서 Multi objective ranking model구성
→ MMoE의 soft parameter sharing 사용 Position Bias를 모델링하고, 모델의 단순화가 필요하다는 결론
'DeepLearning' 카테고리의 다른 글
| Example for Pytorch (0) | 2022.02.20 |
|---|---|
| BPR, Bayesian Personalized Ranking from Implicit feedback, Rendle (0) | 2021.10.16 |
주된 차별점
- 2Stage Model
- Multiple Ranking Objective
- Multitask
- Implicit Feedback ( feedback loop )
- Bias ( Selection Bias == Position Bias )
어떻게 추천할 것인가?
(예시상황)
사람들이 Video platform에서 Video를 계속해서 시청하고있는 상황.
나는 User가 platform에서 더 많은 동영상을 보고, 더 많은 시간을 사용하게하고싶음
→ User가 좋아할만한 동영상을 추천해주자
⇒ '다음동영상'으로 어떤 동영상을 추천해줄 것인가? 에 대한 문제로 귀결됨
그렇다면 무슨 기준으로 추천을 해야할까?
크게 생각했을때는 2가지 기준으로 나눌것이다.
- 일반적으로 사람들이 좋아하는 부류의 동영상을 추천해주기
- 내가 좋아하는 부류의 동영상을 추천해주기
Youtube의 기본화면을 봐보자
(좌)처음유튜브에 들어가본 계정 : 일반적으로 사람들이 좋아하는 부류의 동영상 이 많이 보이는반면,
(우)평소에 사용하는 계정 : 내가 좋아하는 부류의 동영상 이 많이 보이는것을 알수있다
동영상을 직접 눌러서 봐보자
이 경우에는 무한도전에서 '자존심이 상한 꼬마' 라는 썸네일을 가지는 동영상이 유저에게 추천된 경우이다.
시청중인 동영상(무한도전)과 비슷한 동영상(무한도전)이 추천동영상으로써, 댓글창 하단에 위치해있다.
이는, 시청중인 동영상(무한도전)을 'User가 직접 선택했으니' 이 동영상은 'User가 관심있어하는 동영상 일것이다' 라고 생각했고
이를 기반으로 '지금 시청중인 동영상과 비슷한 동영상'을 User에게 보여주면 User도 좋아할것이다. 라는 생각을 기반으로 비슷한 동영상이 추천된것이다.
⇒ 즉, Youtube는 지금 시청중인 동영상을 기준으로 비슷한 동영상을 User에게 추천해준다.
0. Abstract
User가 Video를 선택할때 'User의 주관'이 개입함 ( User는 자기가 보고싶은 동영상을 봄 == '주관')
User가 추천된동영상을 선택하고, 검색창에 검색하고, 동영상들을 시청하고, 다른 동영상을 검색하는행위 ⇒ Implicit Data ⇒ Implicit Feedback (bias)
GOAL : Feedback문제를 해결하기
- Multiple ranking object를 고르는 soft parameter sharing technique
- Wide&Deep framework 를 기반으로 하는 Bias감소방법
1. Introduction
Model Stage구성
Model
Layer1 : Candidate Generation Layer
Layer2 : Ranking Layer
(이 논문은 Ranking Layer에 focusing한 논문)
Layer1에서 Candidates Objectives를 만들고(후보동영상을 만드는과정)
Layer2에서 Dandidate를 대상으로 Ranking모델을 적용함(후보동영상들을 1위~200위까지 줄세움)
→ 후보동영상은 User가 선호하는 순서대로 나열됨
Video시스템을 구축하기위해서 해결해야 할 문제1
선택지가 多인 상황
User가 Video 시청을 다 했음
- 추천선택지1 : 다른 동영상을 시청하기
- 추천선택지2 : 지금 본 동영상을 친구에게 추천해주기
→ 이런상황에서 어떤 선택지를 할것인가??
Video시스템을 구축하기위해서 해결해야 할 문제2
Feedback loop상황
User는 동영상이 'User가 관심있어했던 동영상' or '흥미가 없는 동영상' or '새롭게 흥미가 생기는 동영상'을 시청할수 있음.
근데, 동영상을 선택했을때 유저가 선택한동영상과 비슷한 동영상을 추천해주는 시스템을 채용하고있으니,
User가 흥미가없는 동영상을 시청했을때(User가 싫어하는 동영상)
User에게 추천되는 동영상도 User가 싫어할 것이다. 라는게 Feedback loop이다.
Model Architecture
주요하게 볼 내용
- Input Feature가 2개로 나뉜다(보라색)
- Query and Candidate itmes
- Visual and language and context features
- 주요모델은 2가지로 구성
- 왼쪽의 shallow tower
- 오른쪽의 main tower
- Objectives가 2가지로 구성
- User Engagement
- User Satisfaction Objectives
- Serving할때 Ranking score가 나온다는거
- Traning에서 User logs는 2가지로 구성
- Engagement behaviors
- Satisfaction behaviors
2. 주요모델
- 왼쪽의 shallow tower : ranking selecton bias를 조절하는역할
- 오른쪽의 main tower : MMoE : User의 Action을 예측하는역할
MoE ( Mixture of Experts)
- MMoE ( Multigate Mixture of Experts) : MMoE에서 User의 Action(참여, 만족도) 을 예측함
- Multitask Learning 을 위해서, 기존 Wide&Deep Model에 MMoE개념을 추가한것이라고 봐야함
User log
User가 행동했던 모든 것들이 Log임 (Multiple Objective)
- User가 직접 참여하는 종류의 Log
- User가 동영상을 클릭하는 행위
- 추천된 동영상을 User가 보는 행위
- User가 동영상에 만족하는 종류의 Log
- 영상에 대하여 좋아요를 누르는 행위
- 영상을 보는중에, 영상을 그만보는 행위
→ 1과 2에 중복되는 Log가 존재할수 있음
(User가 직접 참여하면서 && User가 동영상에 만족하는행위)
⇒ Shallow tower로 해결함
Gating networks + MMoE
MoE는 Input layer를 Expert로 모듈화 시키고, Layer 마다 Input의 서로 다른 부분을 받는다.
: 2가지로 나뉜 Object는 Input Layer의 서로다른 모듈로 들어간다.
이런식으로 input을 받으면 Object에 대한 현상을좀더 객관화시킬수있음
Multiple Gating Networks를 통해서 Object마다 experts를 선택하여 다른사용자과 공유하거나, 공유하지않을수 있음
Input features
input features(training data)를 2개의 부분으로 나눈다.
main model부분에서 학습되었으나, unbiased된 user utility
shallow tower에서 학습된, estimated된 propensity score
Shallow Tower
input features에서 selection bias(ex. position bias)를 modeling하고 reduce하기위해서 존재함.
input으로는 selection bias와 관련된 것(ex. ranking순위) 들을 받고
output으로는 scalar를 도출한다.(이때의 scalar는 최종예측에 큰 영향을 주는 bias이다)
Model Architecture구성이 가지는 의미
이러한 전체모델구성은(main model + shallow tower)
Wide &Deep모델의 확장으로도 볼수있을것이고
shallow tower가 Wide부분을 맡는다고 보면된다.
이러한 내용을 통해서 propensity score를 얻기위해 무작위 실험에 의존하지않고,
selection bias를 학습하는 이점을 가진다.
Architecture의 효과를 검증하기위해 Multitask learning Removing a common type of selection bias(e.g. position bias) 해당 내용에 대해서 offline과 LIVE실험을 진행하였음
End to End + Ranking
1. Ranking 문제를 multi-objective learning로 공식화
2. MMoE로의 확장
3. Wide & Deep 모델의 확장
4. position bias의 문제를 해결하는것
5. real world scale의 video recommendtaion시스템에 적용했다는것에 의의를 가진다.
2. Related Work : Query
Recommendation == high utility item반환하는 문제 (이때 사용하는 User log는 User의 Histroy가 사용됨)
e.g User가 Friday night에 tablet으로 home에서 movies를 봤다면?
Who : User
Time : Friday night
Device : tablet
Where : Home
What : movies
이런식으로 Query를 구성할수 있음
2.1 Industrial Recommendation Systems : Explicit or Implicit여부
Training Dataset의 부족 (Implicit Data만 사용함) → explicit feedback으로 해결하려고했음
현실적으로는 explicit feedback의 경우 비용때문에 실행하기는 어려움
→ click이나, 추천된 items를 보는것에 참여하는 User의 참여형태로 존재하는 implicit feedback 를 사용한다.
2.2 Multi-Objective Learning for Recommendation Systems
해결해야할 문제 : 동영상을 클릭해서 봤지만, User 마음에 들지않는경우
→ 클릭된 video에만 점수매길수있는 시스템특성상 마음에들지않은 Video에도 Score를 줄수밖에없음
⇒ 싫어하는 Video가 계속 추천되는 상황이 발생함
해결방안
User behavior + utilities의 결합 → User behavior를 Train & Estimate
→ 결과를 Combine → Final utility score를 계산함 ⇒ Ranking(줄세우기)
기존모델의 단점
- CF or CB의 user-item 유사도를 확장한 모델
- 기존모델은 Candidate generation단계에서는 매우 효과적이지만
- DNN을 사용한 ranking모델과 비교했을때 Final recommendtaion에서 덜효과적임
- Text or Vision을 대상으로 하는 Multi Objectie Ranking모델
- 기존모델을 유튜브썸네일이나 이런곳에는 사용하기 좋겠지만
- sharing model parameter를 효과적으로 처리하지못해서 비효율적
2.3 Understanding and Modeling Biases in Training Data : Feedback & Feedback
Training Data로 사용하는 User behavior → User feedback(User log)
→ User behavior는 selection biases를 제거해야하는 목표가 생김
Current System에서 가장 Video를 1~10위까지 추천해주었는데, User가 1순위 video를 선택했을때
→ 이 경우에도 feedback이 발생함
( click data와 explitcit feedback을 비교했봤는데. click data에 position bias가 존재하고, QUERY와 DOCUMENTS 사이에서 position bias(selection bias)가 문제를 일으키기에 [23,34,31]에서 제거를 하려는 시도를 했었음)
Selection Bias를제거하는법
Model
1. input feature로 position을 inject +model을 traning
2. serving할때 bias를 제거하여서 사용함
Probablistic click Model
: P(relavance | pos) == 추천된 위치당, 선택될 확률
CTR Model
P(relavance | pos)
→ position이 1일때, 평가에 대한 position bias가 0 이된다는것을 사용함
⇒ position bias를 제거하기위해서, input feautre로 position정보를 사용 && position feature 값을 1로 설정(혹은, missing value나 다른수치로 고정)
3. Problem Description
우리의 모델 : 2stage Architecture
1Layer : Candidate Generation
2Layer : Ranking
Ranking 시스템에서 생기는 문제들
☆Multimodal feature space
☆Scalability
Multimodal feature space
조건 : Context-aware personalized RS
목표 : multiple modalities 기반으로 -> User utility를 도출해내야함
이유 : Multimodal feature space에서 라는 특징때문
도출하는 것들
- Low level content로 부터 semantic 격차를 해소함 (Content filering를 잘하기위하려는 목적)
- item의 분포가 sparse distribution인 상황에서의 learning (Collaborative filtering에서 사용하려는 목적)
Scalability
기반 : Youtube
특징1 : 수십억명의 User + 매우多동영상의 플랫폼
→ Ranking 시스템에서 하나의 Query가 수백개의 Candidate’s score에 영향을 줌
특징2 : Real-world scenario
→ 일부 Query와 Context 정보는 Online단계에서만 사용가능함
→ 모델은 서비스를 제공(serving)하는 동시에 items과 users에 대한 학습을 진행할수 있어야함
Paper's goal
상황 : 현재 User가 Video && Context를 보고있는 상태에서 ranked list of video를 제공
목표 : multimodal feature space 정제 방법 :
- Video -> ( Video meta data + Video Content Signal)
- Context -> (user demographics + device + time + location …)
- Candidate generation stage :huge corpus로부터 a few hundred candidate를 검색하고(뽑아내고)
- Ranking stage :Candidate들에게 score를 기반으로 하는 ranked list를 제공
3.1 Candidate Generation : Multiple candidate generation algorithm
stage1 : Multiple candidate generation algorithm 사용
→ 각각의 algorithm은 Query video와 Candidate video의 유사성의 일부분을 capture 하는역할을 함
논문에서 User log(History)를 사용하기위한 sequence 특성
(Context-aware high recall relevant candidate를 하는 특성)
⇒ Stage1의 마지막에서는 모든 Candidates가 하나의 set으로 풀링 && 그 후에 순위 체계에 의해서 Score화
*Multiple candidate generation algorithm?
- 하나의 알고리즘이 Query video의 topic을 matching시켜서 candidate video를 만들고
- 또다른 알고리즘이 Query video와 함께 video를 시청한 빈도를 기준으로 Candidate video를 검색하는 방식
3.2 Ranking
input : Stage1에서 output으로 보내주는 Candidate set
Output : User가 좋아할만한 ranked list itmes (item utility)
4. Model Architecture
다룰 내용은 3부분임
- Multi objective setup: multiple types of user behaviors를 학습하기위함
- state-of-the-art multitask learning model architecture: 적용 및 확장
- MMOE && shallow tower를 통해서 training를 진행하고, 이때 생기는 selection bias(position bias)를 제거하는 방법에 대한 설명
4.1 System Overview : Ranking → Multiple Objective
Stage2의 input : Candidate의 feature(Query and context)
Stage2의 goal : User가 어떻게 행동하는지 predict 하는법을 학습
Learning to rank framework를 적용 -> Stage2의 Ranking problem을 Multiple objectives를 가지는 Classification문제 && Regression문제로 바꿨다.
Training Data : User feedback의 종류
- User가 참여하는 행동(e.g. 비디오를 Click & Watch)
- User의 만족도 행동(e.g. 비디오에 대해서 LIKE버튼을 누르는 행동)
User feedback 을 기반으로 Stage1에서 Candidate가 도출됨
Stage2에서는 Stage1의 Candidate의 feature기반으로 User behavior를 예측하는 방법을학습함
Point-wise vs Pair-wise, List-wise
Pair-wise or List-wise 방법 :
Multiple candidates에 대해서 prediction하는 방법을 Train가능함 (->multiple candidates로부터 Recommendation의 diversity 확장가능) Candidates의 조합에 대해서, Scoring하는 과정이 많기때문에 확장성의 제한이 있음
Point-wise
1. Serving할때 simple && large scale에 efficient 하다는 특징
2. Point-wise방법사용
4.2 Ranking Objectives
Training Label로 사용하는것 : User behaviors
추천되는 recommended items 에 대해서, User는 多동작을 할수있음
→ Multiple objectives로 나눌 수 있음
1개의 Objective당, 1개의 user utility만을 prediction에 사용
Objectives 를
- Engagement Objectives와
- Satisfaction Objectives로 구분함
Engagement Objective-> Binary Classification + Regression
Engagement Objective ==Binary Classification+ Regression
Binary classification task (e.g. 동영상, 좋아요 버튼의 클릭여부)
Regression task (동영상을 보는데에 대한 시간을 얼마나 사용하였는지)
Loss 사용 : Binary classification task : cross entropy loss Regression task : squared loss (e.g.MSE)
4.3 Modeling Task Relations and Conflicts with Multi-gate Mixture-of-Experts
일반적인 shared bottom 구조 사용시Multiple objectives에 대한 Conflicts(충돌)문제가 생김
→ MMoE를 사용해서 해결
MMoE (Multi-gate Mixture of Experts)
soft-parameter sharing model structure : task conflicts && relations를 모델화하기 위함
MoE를 모든 task에 대해서 공유하고, 각각의 task에 대해서 gating network를 훈련시킨다
⇒ MoE구조를 Multitask learning화 시킨다 :: MMoE
일반적인 Multiple objective를 사용하는 Ranking system : shared bottom Layer의 구성
그러나 이런식의 hard-parameter sharing기술은 task간의 Correlation(상관관계)가 낮을때 Multiple objectives에 대해서 충돌문제가 생길수도있음
MOE
Expert Layer
→ Modularized된 information으로부터 Learning에 도움을 줌 ⇒ Input Layer또는 Hidden layer에서 Multi modal feature space구현에 도움됨
왼쪽(기존) 오른쪽(MMoE) 의 차이
Shared bottom layer 1개 && Task Layer 1개 -> Expert Layer 2개로 바꿨음
주의점
MoE를 input Layer에다가 적용시 model traning && serving 할때 Cost가 증가한다는 단점이 있고 (이유 : Input Layer의 차원이 hidden layer보다 고차원이기때문)
4.4 Modeling and Removing Position and Selection Biases
Implicit feedback 기존방식 : rank model에서 learning을 train하기위해서 사용
매우많은 양의 User logs로부터 추출된 Implicit feedback은 복잡한 DNN 기반 모델을 train시킬수 있음
※ implicit feedback은 현재 존재하는 ranking system에 의해서 생성되었다는 것 때문에 편향(biased)되었다는걸 알아둬야함 (의역 : Data를 뽑아내는 유튜브의 경우. 어쨋든 유튜브 자체도 ranking system에 의해서 만들어진 프레임이기떄문에, 여기서 뽑아내는 Data가 순수한 Data가 아니라, 편향되었다는것을 알아두어야한다)
Selection Bias(Position bias)
일반적으로 사용자는
- 상단에 추천된 Video의 user utility와 이전에봤던 video의 연관성과 상관없이, 상단에 추천된 Video를 클릭하고 시청하는 경향이 존재함
→ 목적 : 이러한 Position bias를 제거해줘야함
Traning data의 selection bias를 제거하고 모델링
→ Model의 퀄리티 상승 && selection bias에서 생성되는 feedback loop를 break시킬수있음
※ User는 상단에 있는 영상이 내가 좋아할만한것, 내가 좋아하지않을만한 것이여도 무조건적으로 상단의 영상을 클릭하고 시청하는 경향이 발견되었음
Model = main tower + shallow tower
Model Architecture에서
a user utility component->(main tower)
bias component -> (shallow tower)
Shallow tower 구성하는 이유
Train할때
- 모든 impressions의 positions값이 사용되고
- 10%의 feature drop-out rate를 설정→ position feature에 Overfitting을 방지함
Serving할때
- position feature는 사용하지않는다.
※ Serving할때 position feature를 사용하지않는이유 (position feature와 device feature를 교차전달해주지않는이유 ) : devices의 different types의 different position bias가 관측되기 때문이다.
5. Experiment results
실제 실험 : Youtube
Implicit feedback + Offline expertment +Live experiments
Implicit feedback을 사용하여, ranking model을 train할것이고,
offline experiments와 live experiments로 test를 진행함
실험대상이 Youtube 인 이유 :
거대한 규모와 복잡성을 가지고있음 : testbed로 사용하기에 좋음
User가 recommended results와 상호작용을 하는 user activities가 무지막지하게나옴
next video를 추천해줌
User interaction : click, watch, like, dismissal 같은 선택지가 존재함
Offline experiment
Classfication task에 대한 AUC && Regression task에 대한 squared error를 구한다.
Live experiment
A/B Test를 진행함
A/B Test
원인과 결과를 찾는 테스트 e.g. 물놀이 익사사고랑 아이스크림 가격의 연관성
→ 물놀이하는곳 근처에 아이스크림을 팔고있으니 아이스크림 가격을 올리면, 사람들이 물놀이하러 덜 갈것이고 그러면 자연스레 익사사고 수가 줄어들것이다…
Offline실험과 Live실험은 learning rate같은 hyper parameter로 조정해서 사용한다
Youtube == Realtime application
과거~현재 Data : Model train에사용 현재Data ~ing : 지속적으로 training → 가장 최근의 Data에 적응함
5.2.1 Baseline Methods
Baseline method :
- shared-bottom model architecture (Figure 2a)
Model complexity : (복잡성)
- Multiplication in Model architecture -> Effeciency 小
⇒ MMoE Layer는 Input layer보다 lower dimensionality를 사용하는 bottom hidden layer를 공유한다(Figure 2b)
5.2.2 Live Experiment Results
5.2.3 Gating Network Distribution
5.2.4 Gating Network Stablity
MMoE에서 softmax gating networks가 가지는 문제 Imbalanced expert distribution problem (불균형)
불균형문제-> Gating network의 polarization발생 (model performance에 악영향)
해결책으로 Gating network에 drop-out을 적용해서 Polarization을 제거함
5.3 Modeling and ReducingPosition Bias
Input으로 사용하는 Data : User feedback
Implicit feedback 와 true user utility에 대한 차이를 제거해야함
→ 경량화된 모델을 사용하여서 SelectionBias를 모델링하고
→ 줄이는 방법을 사용하였음
5.3.1 Analysis of User Implicit Feedback
위치별 클릭률을 비교 1(상단)~9(하단)
상단의 item 클릭률이 압도적으로 높다
CTR : Click thourh rates 클릭률
상단의 CTR이 높은 이유:
더 관련성이 높은 항목 && Position Bias 때문
Shallow Tower를 사용해서
Position bias가 제안된 접근 방식을 사용하여 User Utility 와 Position Bias의 분리를 입증함
5.3.2 Baseline Methods
Directly using position feature as an input feature : Position 값 자체를 input feature라고 사용하는것
Adversarial learning : Traning Data의 position을 예측하는 단계를 도입
→ 이후 back propagation phase에서 Grdient를 반대로줘서, Model의 prediction이 position feature에 영향을 받지않게함
5.3.3 Live Experiment Results
Position Bias를 모델링해서 실험해봤더니 Engagement Metirc이 향상됨
5.3.4 Learned Position Biases
5.4.1 Neural Network Model Architecture for Recommendation and Ranking
- Multimodal feature spaces.
- Query의 내용, item, context 같은 다양한 feature
- Scalability and multiple ranking objectives
- 다양한 Objectvies에 동시에 적용하기 힘듬
- Noisy and locally sparse training data.
- 대부분의 희소기능은 사용량이 적음 → embedding space 를 최적화 하는것에 어려움이 있음 (ex. Longtail. 80:20분포)
- Distributed training with mini-batch stochastic gradient descent
- 대규모의 신경망 모델을 사용해야함 -> Data가 많기때문에 분산학습을 진행해야함
5.4.2 Tradeoff between Effectiveness and Efficiency.
효과가 매우높은모델(유저가 매우 좋아할만한 item을 뽑는것) → Cost소모가 크고, Time이 오래걸린다 → User가 싫어함
⇒효율성에도 신경써야함
5.4.3 Biases in Training Data
Position Bias : 현재논문에서 가장 문제로 삼고있는 Bias
But. 논문에서 밝히지 못한 Bias가 더 있을것이라고 판단하였음 (아직은 모름)
5.4.4 Evaluation Challenge
Test는 Offline test + Live test 로 진행함 (즉, Offline test의 성능이 Live test의 성능에 바로적용되지 않음)
→ 더욱 더 simple한 모델이 필요하다고 판단함
5.4.5 Future Directions
앞으로의 Ranking system의 방향성
Exploring new model architecture for multi-objective ranking which balances stability, trainability and expressiveness.
Understanding and learning to factorize.
Model compression.
6. Conclusion
Training Data의 User implicit feedback이 문제점이였고
특히 Position Bias가 문제였음
→ 해결하기위해서 Multi objective ranking model구성
→ MMoE의 soft parameter sharing 사용 Position Bias를 모델링하고, 모델의 단순화가 필요하다는 결론
'DeepLearning' 카테고리의 다른 글
| Example for Pytorch (0) | 2022.02.20 |
|---|---|
| BPR, Bayesian Personalized Ranking from Implicit feedback, Rendle (0) | 2021.10.16 |