
DASK 란 무엇인가
두가지 목적에 의해 만들어졌다

- 연산작업 최적화를 위한 동적 작업 스케쥴링기능
- 분산환경으로 올려서 처리하는 병렬화 기능
DASK 의 구성
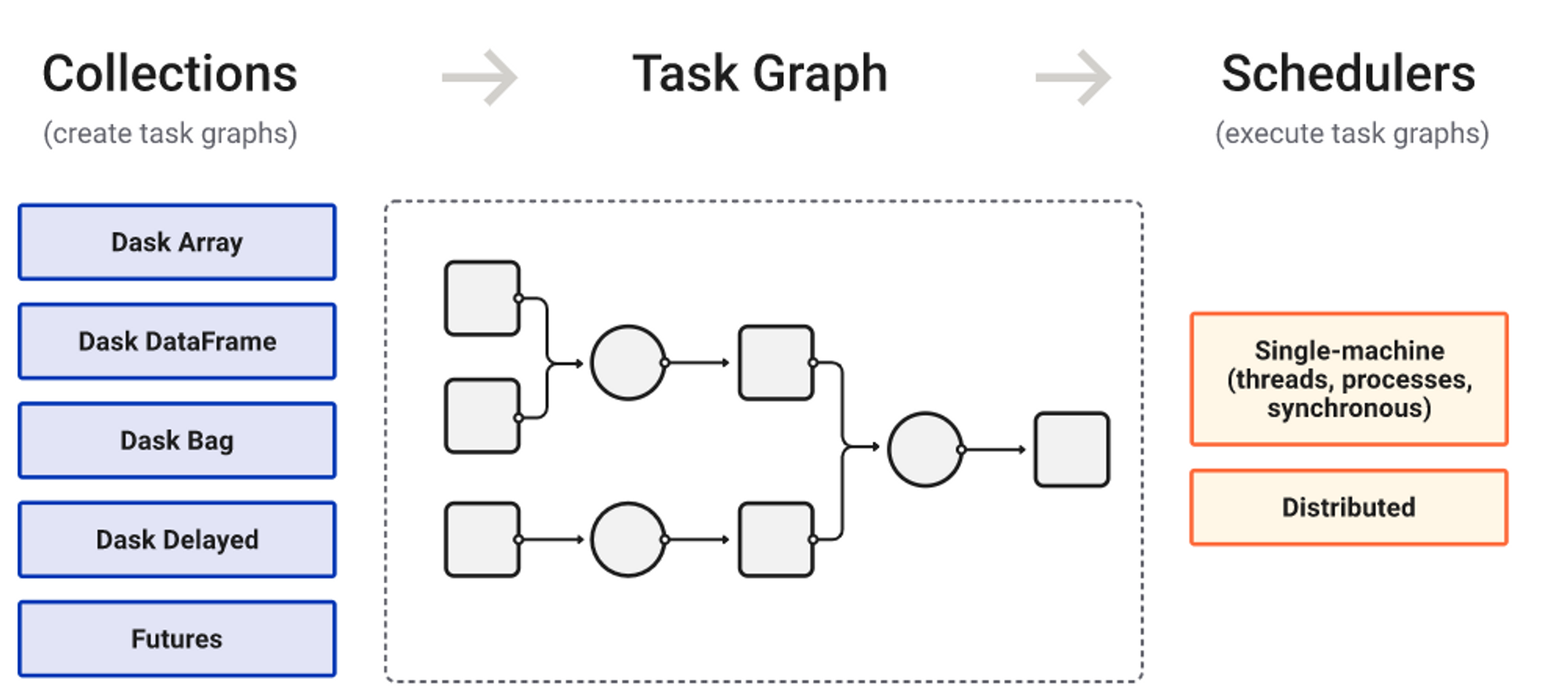
Collections → Task Graph → Schedulers 의 세 부분으로 구성되어있다
DASK DataFrame
특징
- Dask dataframe은 pandas dataframes을 기반으로 구현이 되었음
- 따라서 Dask dataframe 작업은, Pandas dataframe 작업을 기반으로 작동한다고 생각하면 됨
- dask Dataframe은 pandas Dataframe API를 비슷하게 사용할수 있음
- 현재 사용가능한 환경을 넘어서, 더 많은 리소스를 사용할수 있는 환경에서 연산이 가능하게 됨
- Dask Dataframe는 row-wise로 저장되어있고, row별로 group화 되어있음
- 출처 : https://docs.dask.org/en/stable/dataframe.html
사용해야 할, 사용하지 말아야할 상황

dask dataframe를 사용하기 좋을때
- 대용량 데이터 세트를 조작할때
- 많은 코어를 사용하는 계산을 가속화시킬때
- 대규모 데이터세트에 대한 분산컴퓨팅이 필요할때
dask dataframe를 사용하기 안좋을때
- 굳이 병렬처리가 필요 없는경우(⇒
pandas) - 데이터세트가 pandas table형식에 맞지않는경우(⇒
dask.bagordask.array) - 제공되는 기능보다 더 많은 기능이 필요한경우(⇒
dask.delayed) - 광범위하게 적용할수 있는 DB가 필요한경우(⇒
Postgres)
DASK Dataframe을 사용할때 꿀팁
Full-Data Shuffling을 피하기
index설정하는건 중요하지만, 리소스 랑 시간 소모가 크다set_indexmerge/join등의 Full-Data Shuffling 계열은 최대한 적게 사용하는것을 추천한다set_index값은, 최대한 적게 변경하는것을 추천하므로, 처음 설정할때 충분한 논의를 거치는게 좋다
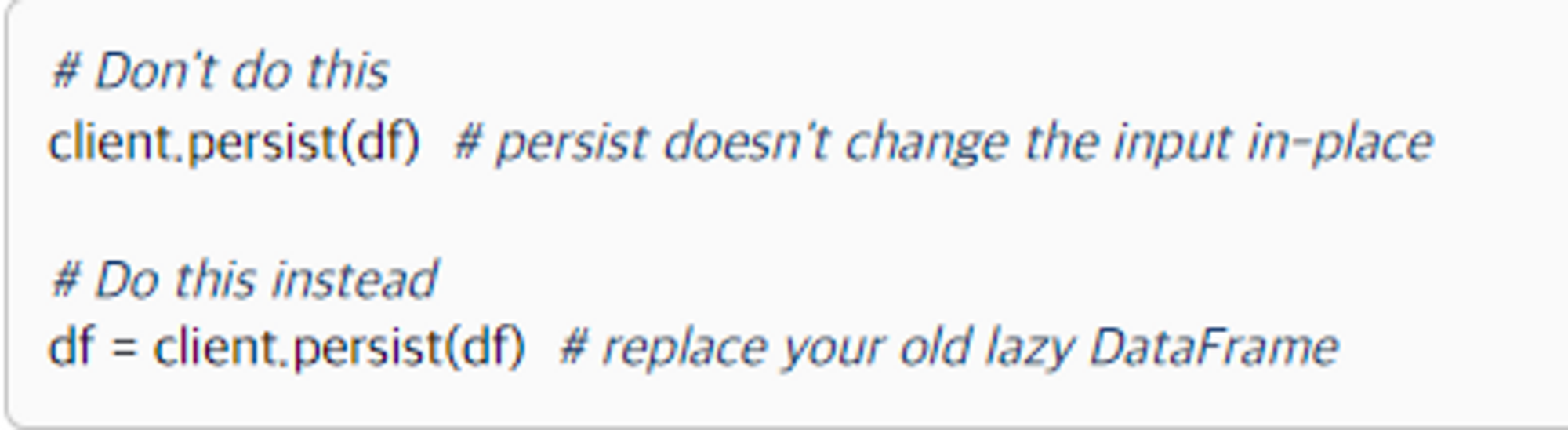
client.persist를 사용하기
- 대부분의 Workload는 다음과 같이 진행된다
- 파일로부터 데이터를 로드하기 → 특정한 집합에 대해서 필터를 적용하고
→intelligent index를 설정하기 위한 데이터 셔플 진행하기 → 인덱스된 데이터에 대한 복잡한 Query를 날리기 load,filter,shuffle은 한번만 작동하고, in-memory에서 결과를 가지고있다- Query를 날리는 작업은 여러번 작동하고, DISK에서 결과를 가지고있으므로
→ In-memory로 작업하면 속도향상이 있을것이라고 예상가능하다
Partitions
- Dask Dataframe은 여러개의 partition로 구분된다
- 각각의 partition은 하나의 pandas dataframe이다.
- ⇒ 하나의 Dask Dataframe은 여러개의 Pandas Dataframe이 모여서 구성된것이라고 이해하면 된다
- 일반적으로는 Dask Dataframe들은 index를 기준으로 구분되고, 각각의 파티션에 있는 index를 확인할수 있다
npartitions, divisions로 파티션의 갯수와 정보를 알수있음
Groupby

- 일반적으로
groupby의 반환 객체는 1개고, 이루는 파티션 갯수 도 1개임 - 근데 파티션의 갯수를 2개 이상으로 지정해줘야할때(용량이 너무 큰경우) 가 존재하는데
split_out옵션을 사용할수 있다. split_out으로 1개의 객체에 여러개의 partitions를 지정해주는게 가능함
Shuffling
- Dask는 판다스에서 API를 따왔지만, 대용량 데이터의 경우에는
groupby, join, set_index는 판다스와는 다른 방안을 모색해야함
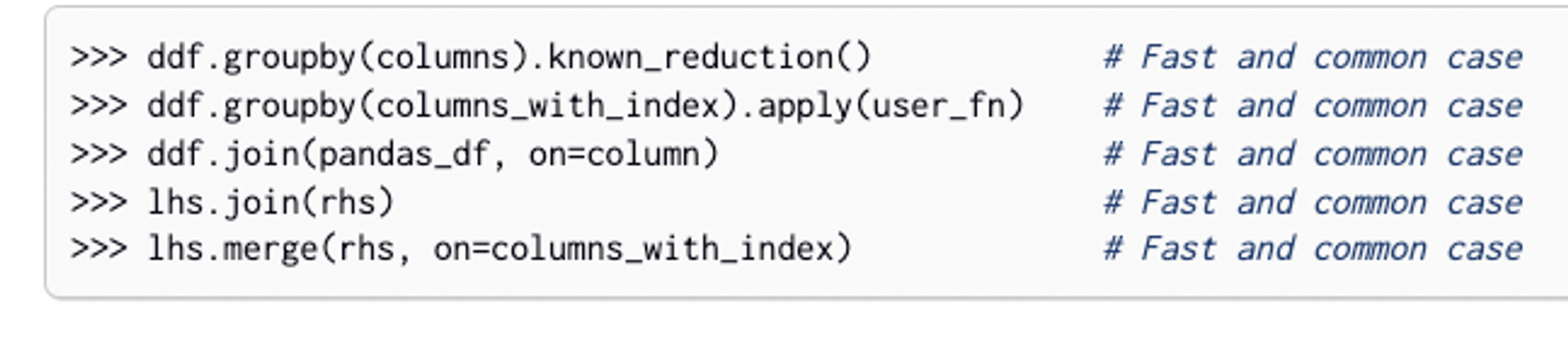
- 일반적인 대부분의 경우에는 그냥 평소처럼 써도 됨

- 인덱스에 따라서 조인하지않고, 열을 기준으로 조인할때
정렬되지 않은 열을 인덱스로 조인해야할때는 전체데이터를 셔플해줘야한다
Shuffling 전략
선택할수 있는 셔플전략은 크게 Shuffle on Disk, Shuffle over the Network 로 구분된다.
- Shuffle on Disk
- 싱글머신에서 메모리보다 큰 데이터를 작업할때, 연산의 중간결과를 Disk에 잠깐 써두는 방식
- partd프로젝트
- Shuffle over the Network
- 분산클러스터에서는 Dask worker는 공유된 하드드라이브에 접근을 못한다는점을 이용한다
- INPUT으로 들어오는 partitions를 많은 조각으로 쪼개서
네트워크 전체에서 조각들을 이동하면서 데이터를 섞는다 - 이런식으로 과정을 만들게되면 task스케쥴러에는 무리가 가겠지만
- 전체를 섞는 과정을 n2** 에서 nlog(n) 으로 만들수 있다
default옵션은on-disk이고,dask.config.set(shuffle=””)옵션으로 지정해줄수 있다
'DATA Engineering > Dask' 카테고리의 다른 글
| DASK Scheduler설명. Client (0) | 2022.11.01 |
|---|---|
| DASK DELAYED. Compute. Futures (0) | 2022.11.01 |
DASK 란 무엇인가
두가지 목적에 의해 만들어졌다
- 연산작업 최적화를 위한 동적 작업 스케쥴링기능
- 분산환경으로 올려서 처리하는 병렬화 기능
DASK 의 구성
Collections → Task Graph → Schedulers 의 세 부분으로 구성되어있다
DASK DataFrame
특징
- Dask dataframe은 pandas dataframes을 기반으로 구현이 되었음
- 따라서 Dask dataframe 작업은, Pandas dataframe 작업을 기반으로 작동한다고 생각하면 됨
- dask Dataframe은 pandas Dataframe API를 비슷하게 사용할수 있음
- 현재 사용가능한 환경을 넘어서, 더 많은 리소스를 사용할수 있는 환경에서 연산이 가능하게 됨
- Dask Dataframe는 row-wise로 저장되어있고, row별로 group화 되어있음
- 출처 : https://docs.dask.org/en/stable/dataframe.html
사용해야 할, 사용하지 말아야할 상황
dask dataframe를 사용하기 좋을때
- 대용량 데이터 세트를 조작할때
- 많은 코어를 사용하는 계산을 가속화시킬때
- 대규모 데이터세트에 대한 분산컴퓨팅이 필요할때
dask dataframe를 사용하기 안좋을때
- 굳이 병렬처리가 필요 없는경우(⇒
pandas) - 데이터세트가 pandas table형식에 맞지않는경우(⇒
dask.bagordask.array) - 제공되는 기능보다 더 많은 기능이 필요한경우(⇒
dask.delayed) - 광범위하게 적용할수 있는 DB가 필요한경우(⇒
Postgres)
DASK Dataframe을 사용할때 꿀팁
Full-Data Shuffling을 피하기
index설정하는건 중요하지만, 리소스 랑 시간 소모가 크다set_indexmerge/join등의 Full-Data Shuffling 계열은 최대한 적게 사용하는것을 추천한다set_index값은, 최대한 적게 변경하는것을 추천하므로, 처음 설정할때 충분한 논의를 거치는게 좋다
client.persist를 사용하기
- 대부분의 Workload는 다음과 같이 진행된다
- 파일로부터 데이터를 로드하기 → 특정한 집합에 대해서 필터를 적용하고
→intelligent index를 설정하기 위한 데이터 셔플 진행하기 → 인덱스된 데이터에 대한 복잡한 Query를 날리기 load,filter,shuffle은 한번만 작동하고, in-memory에서 결과를 가지고있다- Query를 날리는 작업은 여러번 작동하고, DISK에서 결과를 가지고있으므로
→ In-memory로 작업하면 속도향상이 있을것이라고 예상가능하다
Partitions
- Dask Dataframe은 여러개의 partition로 구분된다
- 각각의 partition은 하나의 pandas dataframe이다.
- ⇒ 하나의 Dask Dataframe은 여러개의 Pandas Dataframe이 모여서 구성된것이라고 이해하면 된다
- 일반적으로는 Dask Dataframe들은 index를 기준으로 구분되고, 각각의 파티션에 있는 index를 확인할수 있다
npartitions, divisions로 파티션의 갯수와 정보를 알수있음
Groupby
- 일반적으로
groupby의 반환 객체는 1개고, 이루는 파티션 갯수 도 1개임 - 근데 파티션의 갯수를 2개 이상으로 지정해줘야할때(용량이 너무 큰경우) 가 존재하는데
split_out옵션을 사용할수 있다. split_out으로 1개의 객체에 여러개의 partitions를 지정해주는게 가능함
Shuffling
- Dask는 판다스에서 API를 따왔지만, 대용량 데이터의 경우에는
groupby, join, set_index는 판다스와는 다른 방안을 모색해야함
- 일반적인 대부분의 경우에는 그냥 평소처럼 써도 됨
- 인덱스에 따라서 조인하지않고, 열을 기준으로 조인할때
정렬되지 않은 열을 인덱스로 조인해야할때는 전체데이터를 셔플해줘야한다
Shuffling 전략
선택할수 있는 셔플전략은 크게 Shuffle on Disk, Shuffle over the Network 로 구분된다.
- Shuffle on Disk
- 싱글머신에서 메모리보다 큰 데이터를 작업할때, 연산의 중간결과를 Disk에 잠깐 써두는 방식
- partd프로젝트
- Shuffle over the Network
- 분산클러스터에서는 Dask worker는 공유된 하드드라이브에 접근을 못한다는점을 이용한다
- INPUT으로 들어오는 partitions를 많은 조각으로 쪼개서
네트워크 전체에서 조각들을 이동하면서 데이터를 섞는다 - 이런식으로 과정을 만들게되면 task스케쥴러에는 무리가 가겠지만
- 전체를 섞는 과정을 n2** 에서 nlog(n) 으로 만들수 있다
default옵션은on-disk이고,dask.config.set(shuffle=””)옵션으로 지정해줄수 있다
'DATA Engineering > Dask' 카테고리의 다른 글
| DASK Scheduler설명. Client (0) | 2022.11.01 |
|---|---|
| DASK DELAYED. Compute. Futures (0) | 2022.11.01 |