
선요약
- In-Memory는 데이터의 처리가 끝나지않았다면, 메모리에서 계속 가지고 있는 형식이다
- 읽기 쓰기 횟수를 줄임으로써, 속도를 빠르게 가져갈수 있다
In-Memory 가 뭘까?
쉽게 말해서 In-Memory는 ‘데이터를 메모리 위에서만 가지고 있겠다’ 라는 뜻이다
이해를 돕기위해 Hadoop과 Spark의 자료를 첨부한다
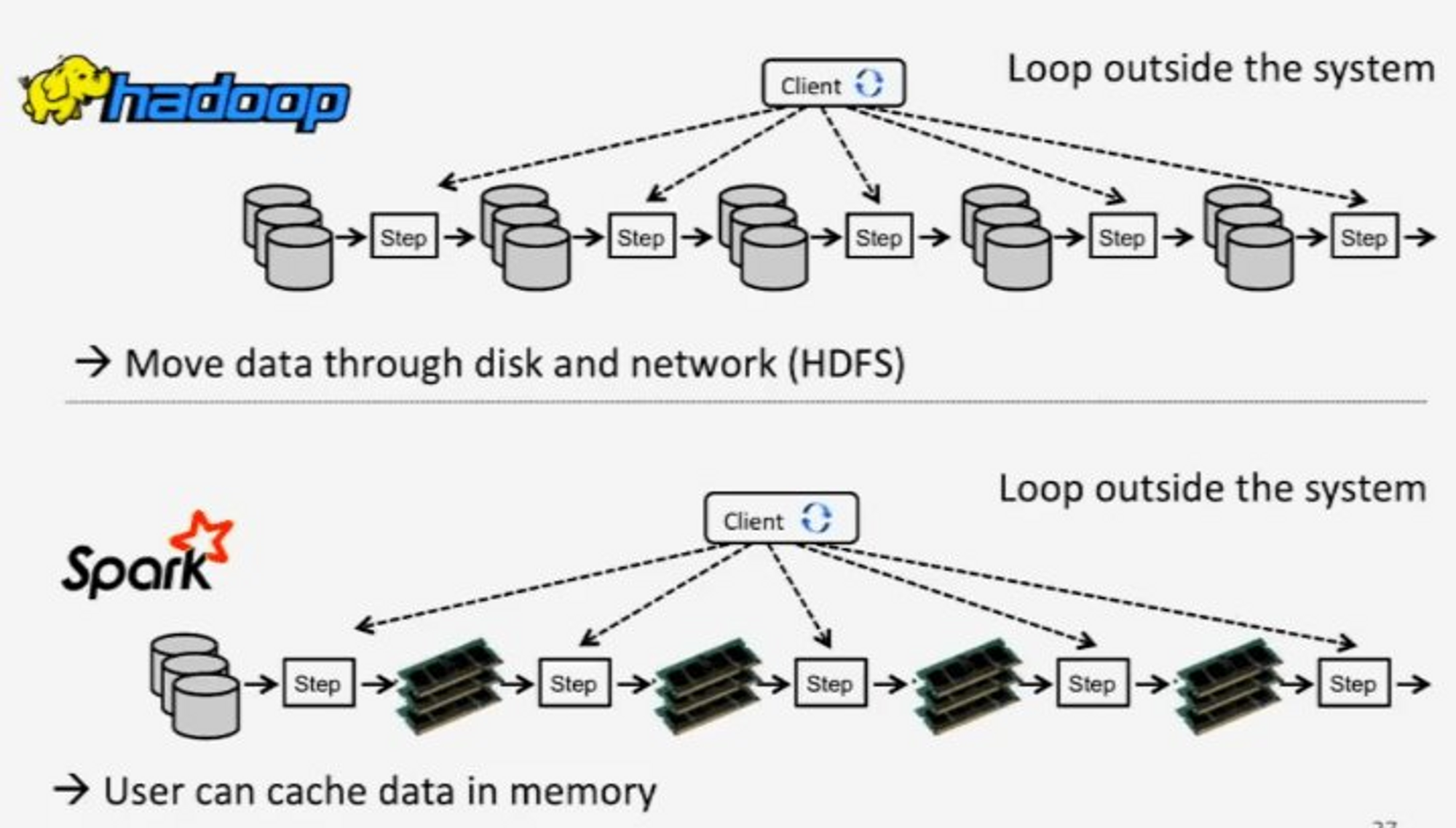
Hadoop은 스토리지에서 데이터를 가져오고, 다시처리해서 스토리지에 넣는 과정을 반복한다
Spark는 스토리지에서 데이터를 가져오고, 다시 처리한다음에 메모리에 넣고, 처리하는 과정을 반복하고, 모든 처리가 끝나면 스토리지에 넣는다
기존방식과 In-Memory의 차이
기존방식
‘Storage’에서 읽고 ‘Memory’에 올린다 →
데이터를 처리하여, ‘Storage’에 넣는다 → [이 과정을 반복한다]
In-Memory방식
‘Storage’에서 읽고 ‘Memory’에 올린다 →
데이터를 처리하고 ‘Storage’에 넣지않고 ‘Memory’가 가지고있는다 → [이 과정을 반복한다]
→ 모든 처리가 끝나면 ‘Storage’에 넣는다
읽고, 마지막에 Storage에 넣는방식
이게 왜 빠른거냐 ?
위에서 나온 예시에서 기존방식은 Hadoop, In-Memory방식은 Spark 다.
쉽게말해서 기존방식은 데이터를 읽고 쓰는 과정이 매우 많다.
Spark는 읽고, 쓰는 과정이 처음 1회 + 마지막2회 밖에 없고
모든 데이터를 Memory에 올려서, 모든 데이터처리를 진행한다.
반면 Hadoop은 모든 처리과정마다 읽고, Memory에 올려서, 다시 써야한다
읽고, 써야하는 과정이 처리횟수마다 한번씩 필요한것이다.
그럼 In-Memory가 무조건 좋은거냐?
그건 또 아니다.
당연한 내용이지만 In-Memory는 데이터 유실에 취약하다.
작업 진행중에 에러가 나서, 처음부터 다시 진행해야하는 상황이라고 생각하자.
Storage에 저장된 데이터는, 다시 불러오기만 하면 되지만
Memory에서 작업진행중이었던 데이터는 모두 유실되었다.
기존 방식으로 진행했던 데이터는, 저장된 데이터로부터 다시 작업을 진행해가면 되지만
In-Memory방식으로 진행했던 데이터는 모두 유실되어, 처음부터 작업을 진행해야한다.
'CS지식' 카테고리의 다른 글
| RAID 전략에 대해서 알아보기 (0) | 2022.11.12 |
|---|---|
| VM vs Container (0) | 2022.11.12 |
| 도커와 가상환경(VM)의 차이 (0) | 2022.07.04 |
| 캐시메모리가 빠른 이유 (0) | 2022.07.04 |
| 파이썬이 C언어보다 느린 이유 (0) | 2022.07.02 |
선요약
- In-Memory는 데이터의 처리가 끝나지않았다면, 메모리에서 계속 가지고 있는 형식이다
- 읽기 쓰기 횟수를 줄임으로써, 속도를 빠르게 가져갈수 있다
In-Memory 가 뭘까?
쉽게 말해서 In-Memory는 ‘데이터를 메모리 위에서만 가지고 있겠다’ 라는 뜻이다
이해를 돕기위해 Hadoop과 Spark의 자료를 첨부한다
Hadoop은 스토리지에서 데이터를 가져오고, 다시처리해서 스토리지에 넣는 과정을 반복한다
Spark는 스토리지에서 데이터를 가져오고, 다시 처리한다음에 메모리에 넣고, 처리하는 과정을 반복하고, 모든 처리가 끝나면 스토리지에 넣는다
기존방식과 In-Memory의 차이
기존방식
‘Storage’에서 읽고 ‘Memory’에 올린다 →
데이터를 처리하여, ‘Storage’에 넣는다 → [이 과정을 반복한다]
In-Memory방식
‘Storage’에서 읽고 ‘Memory’에 올린다 →
데이터를 처리하고 ‘Storage’에 넣지않고 ‘Memory’가 가지고있는다 → [이 과정을 반복한다]
→ 모든 처리가 끝나면 ‘Storage’에 넣는다
읽고, 마지막에 Storage에 넣는방식
이게 왜 빠른거냐 ?
위에서 나온 예시에서 기존방식은 Hadoop, In-Memory방식은 Spark 다.
쉽게말해서 기존방식은 데이터를 읽고 쓰는 과정이 매우 많다.
Spark는 읽고, 쓰는 과정이 처음 1회 + 마지막2회 밖에 없고
모든 데이터를 Memory에 올려서, 모든 데이터처리를 진행한다.
반면 Hadoop은 모든 처리과정마다 읽고, Memory에 올려서, 다시 써야한다
읽고, 써야하는 과정이 처리횟수마다 한번씩 필요한것이다.
그럼 In-Memory가 무조건 좋은거냐?
그건 또 아니다.
당연한 내용이지만 In-Memory는 데이터 유실에 취약하다.
작업 진행중에 에러가 나서, 처음부터 다시 진행해야하는 상황이라고 생각하자.
Storage에 저장된 데이터는, 다시 불러오기만 하면 되지만
Memory에서 작업진행중이었던 데이터는 모두 유실되었다.
기존 방식으로 진행했던 데이터는, 저장된 데이터로부터 다시 작업을 진행해가면 되지만
In-Memory방식으로 진행했던 데이터는 모두 유실되어, 처음부터 작업을 진행해야한다.
'CS지식' 카테고리의 다른 글
| RAID 전략에 대해서 알아보기 (0) | 2022.11.12 |
|---|---|
| VM vs Container (0) | 2022.11.12 |
| 도커와 가상환경(VM)의 차이 (0) | 2022.07.04 |
| 캐시메모리가 빠른 이유 (0) | 2022.07.04 |
| 파이썬이 C언어보다 느린 이유 (0) | 2022.07.02 |